OpenAI has delivered a series of impressive advances in AI that works with language in recent years by taking existing machine-learning algorithms and scaling them up to previously unimagined size. GPT-4, the latest of those projects, was likely trained using trillions of words of text and many thousands of powerful computer chips. The process cost over $100 million.
At the MIT event, Altman was asked if training GPT-4 cost $100 million; he replied, “It’s more than that.”
Anthropic CEO Dario Amodei said in the In Good Company podcast that AI models in development today can cost up to $1 billion to train. Current models like ChatGPT-4o only cost about $100 million, but he expects the cost of training these models to go up to $10 or even $100 billion in as little as three years from now.
OpenAI has not publicly released the cost of training; however in the GPT-5 System Card they claim:
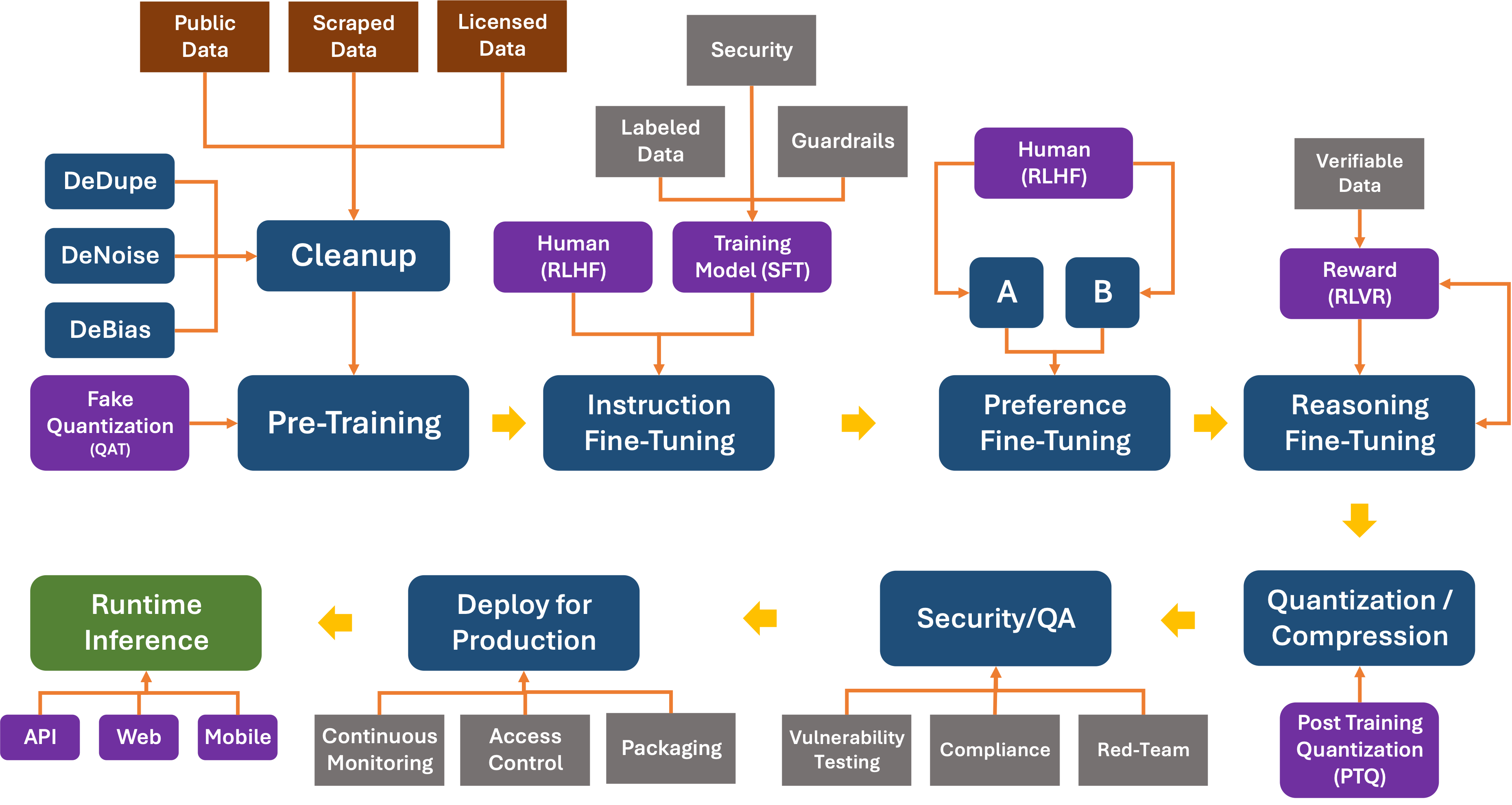
Like OpenAI’s other models, the GPT-5 models were trained on diverse datasets, including information that is publicly available on the internet, information that we partner with third parties to access, and information that our users or human trainers and researchers provide or generate. Our data processing pipeline includes rigorous filtering to maintain data quality and mitigate potential risks. We use advanced data filtering processes to reduce personal information from training data…
…
These models are trained to think before they answer: they can produce a long internal chain of thought before responding to the user. Through training, these models learn to refine their thinking process, try different strategies, and recognize their mistakes.
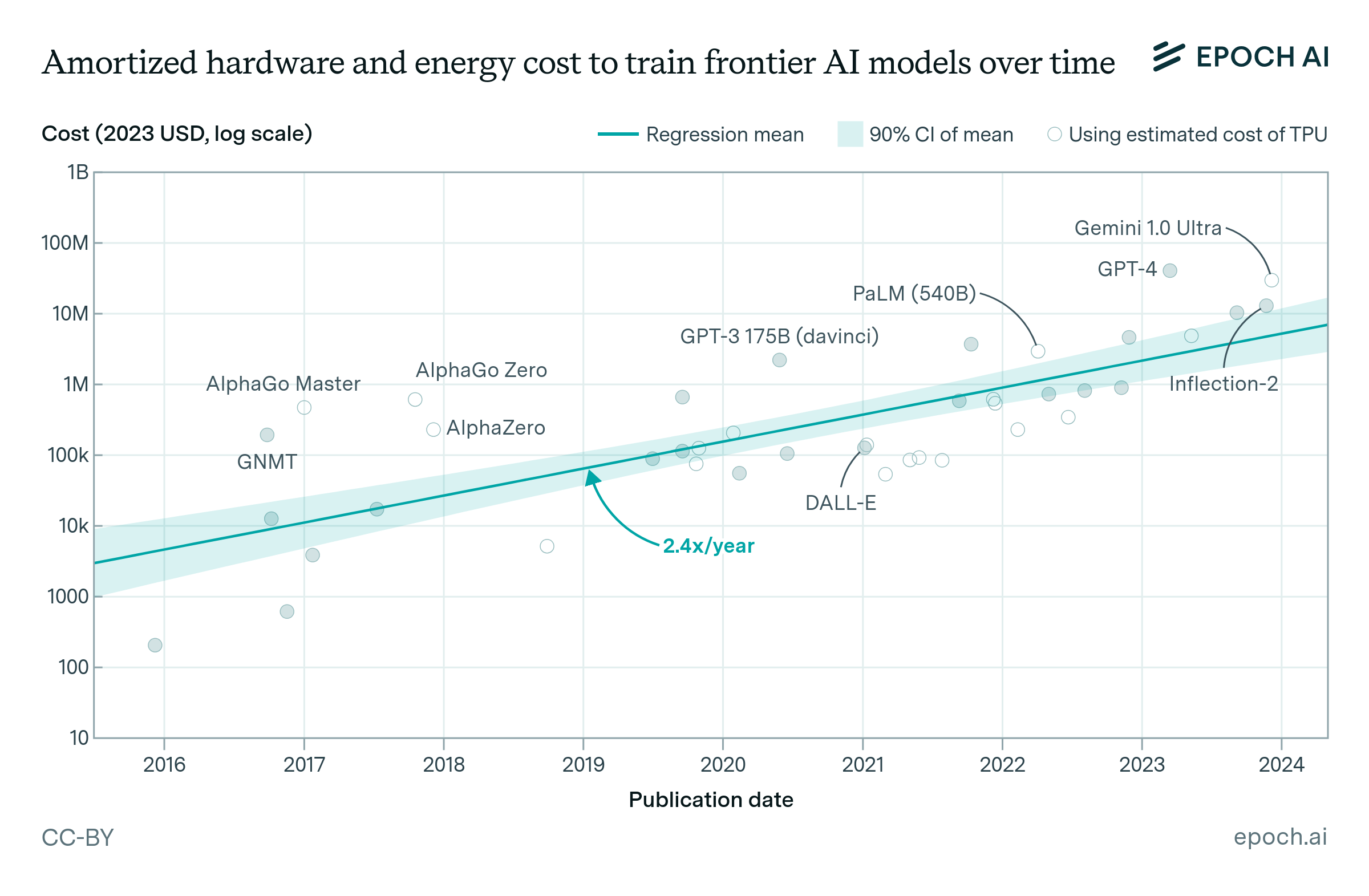
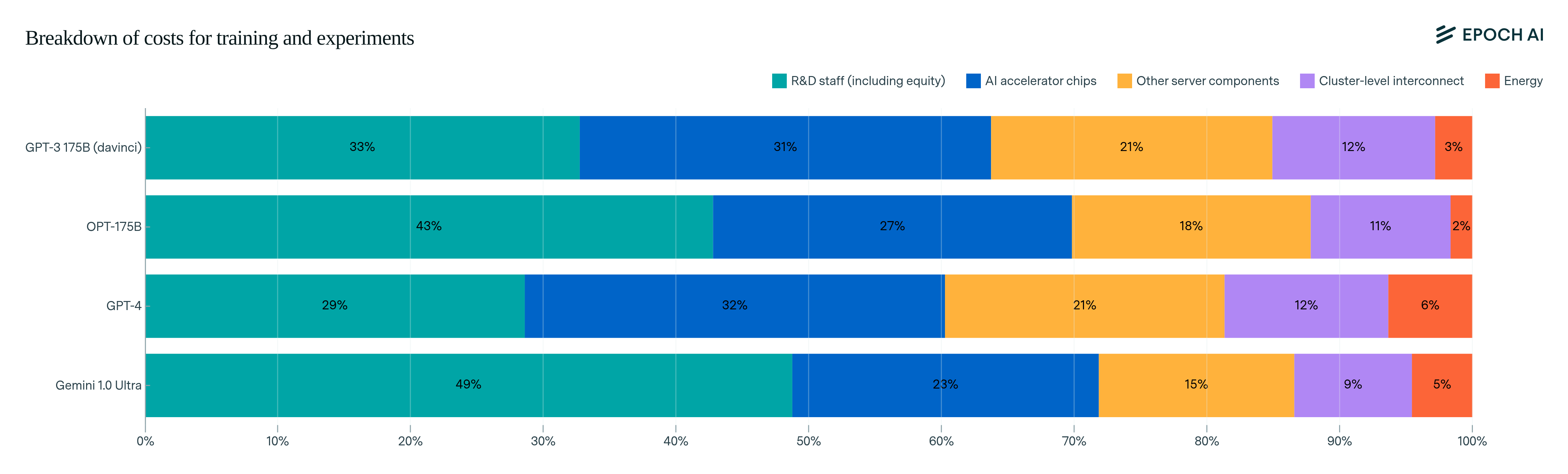
Epoch AI estimates training costs to be on a rising slope:
The rapid increase in AI training costs poses significant challenges. Only a few large organizations can keep up with these expenses, potentially limiting innovation and concentrating influence over frontier AI development. Unless investors are persuaded that these ballooning costs are justified by the economic returns to AI, developers will find it challenging to raise sufficient capital to purchase the amount of hardware needed to continue along this trend.
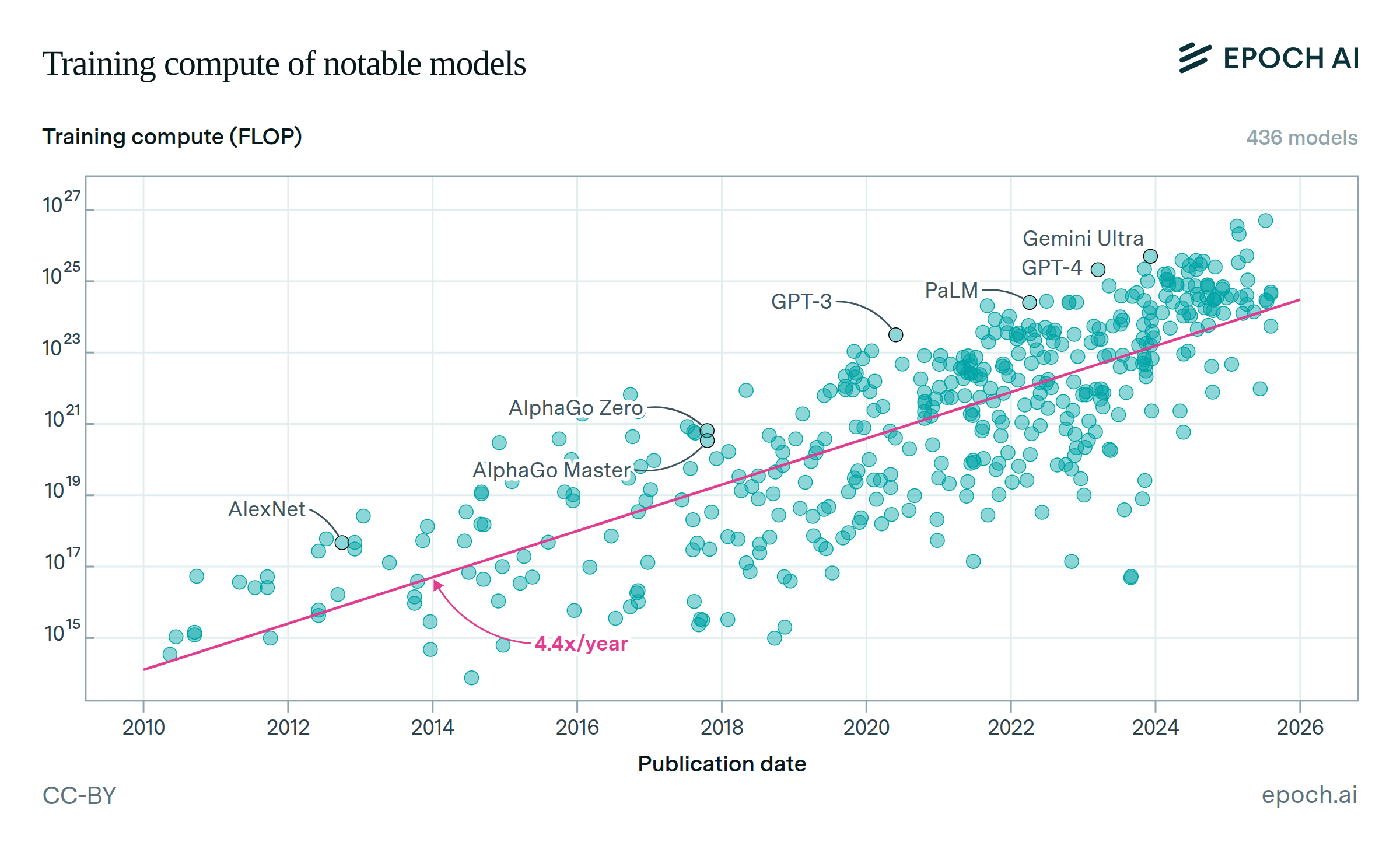
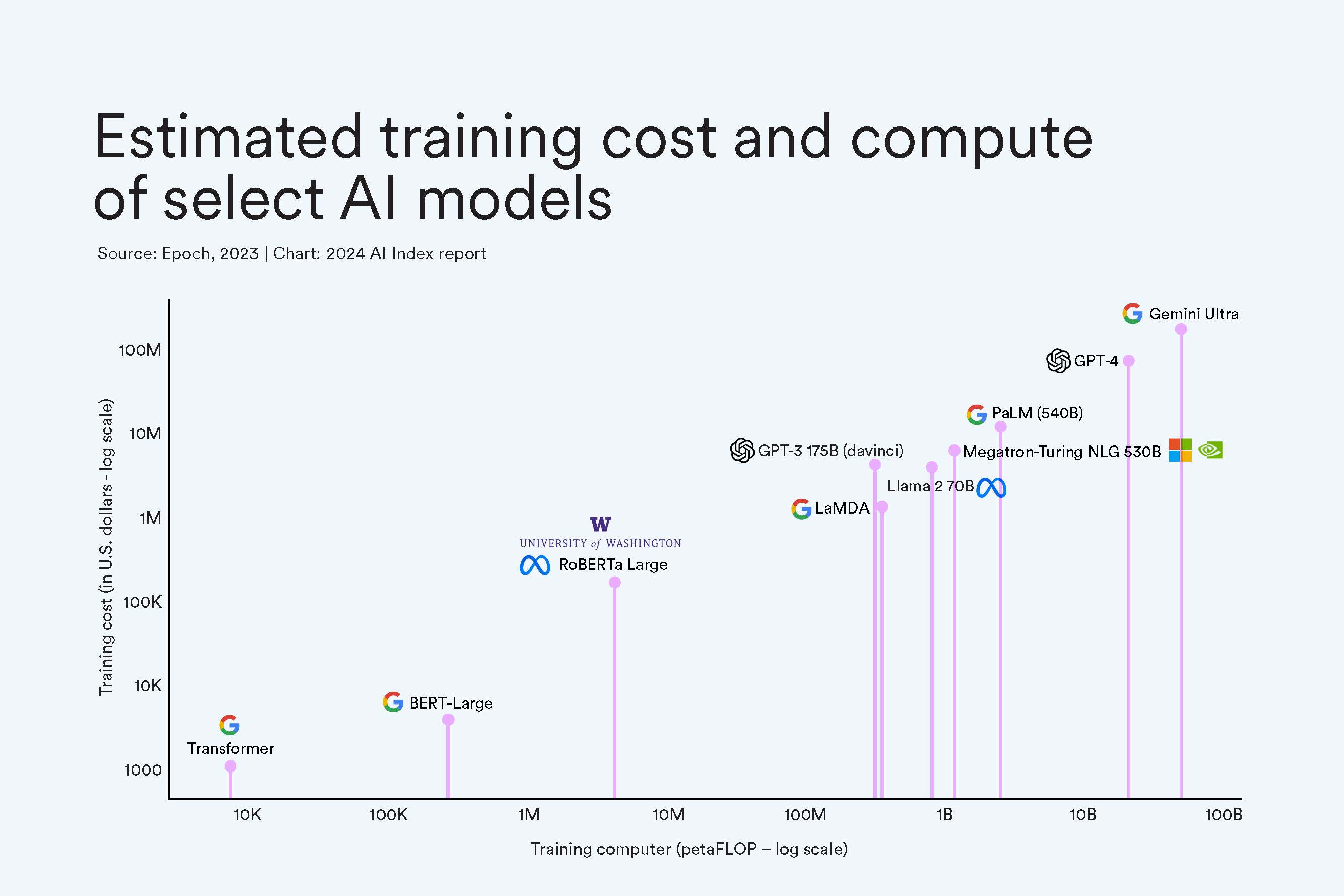
Their most recent estimates show an upward trajectory in computing necessary to train models:
Investors are generally not known for their charity. Historically, this has come at a price.
SHYLOCK
This kindness will I show.
Go with me to a notary, seal me there
Your single bond; and, in a merry sport,
If you repay me not on such a day,
In such a place, such sum or sums as are
Express’d in the condition, let the forfeit Be nominated for an equal pound Of your fair flesh, to be cut off and taken
In what part of your body pleaseth me.
You may want to filter your dataset by the LDNOOBW – List of Dirty, Naughty, Obscene, and Otherwise Bad Words.
Whatever you do, don’t click on the individual files in that list ⬆️. Otherwise, you’ll be spending the rest of your day at The Urban Dictionary clutching your pearls (like I did).
You’ve been warned.
More Data
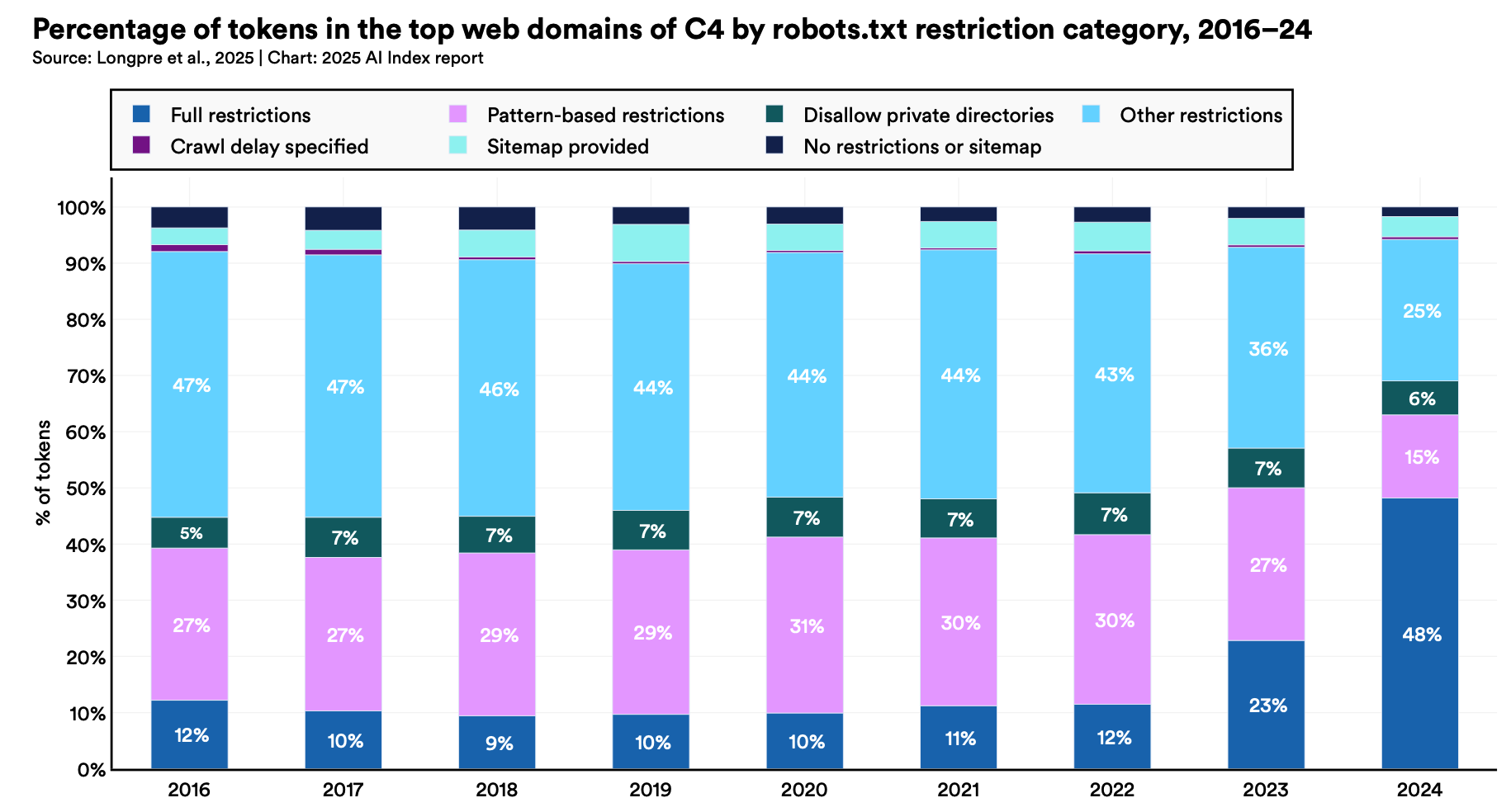
Once all the open-access material has been exhausted, you have no choice but to turn to proprietary content (in some cases, you may want to start there). However, access is getting restricted.
This can lead to wholesale blocking of bots and inevitable accusations of plagiarism, or worse, lawsuits. But data is data. If you’re going down the statistical route, there’s no choice but to feed the beast.
Note, however, that if you try to ignore or find a way around robots.txt blocking your path, you may end up getting throttled by the likes of Cloudflare, fall into open-source tarpits, or get stopped by my own modest contribution, RoboNope.
Despite the availability of open-source data, the cost of acquisition is likely to rise. The corpus of easily-acquired data (aka low-hanging fruit) has already been ingested by the large Foundation Models. Just ask Meta.
This will likely increase as publishers of data, media, and content begin to realize the value of their content and begin to extractlicensingfees for training access.
Publishers with specialty content have woken up to the value of their material and are signing individual licensing deals. Startups like Tollbit are helping prepare for a future of fine-grain data monetization.
On Truth
Colbert Report - Comedy Central
At large scale, verifying the Truthiness of every piece of data may be impractical. Unfortunately, it’s also orthogonal to the current training process. The pipeline works best with material that is variant, that represents typical human output.
Not correct, mind you. Just plausibly typical. And different.
If curating datasets for specific domains, the task is even more arduous. Medical, insurance, and data from other regulated domains are difficult to obtain and harder to verify. There are also privacy and regional rules to navigate:
Using synthetically generated data is one option, but in practice, it may not work so well. Another goal is to improve hardware utilization rates (i.e., MFU) to improve efficiency and maximize existing resources.
Filtering for accuracy at scale, like content moderation in social media, may well be impossible.
Like the old CPU Megahertz Myth, we may well reach the conclusion that it’s no longer about how many billions of parameters a model has, but how well those parameters are suited to the task at hand.
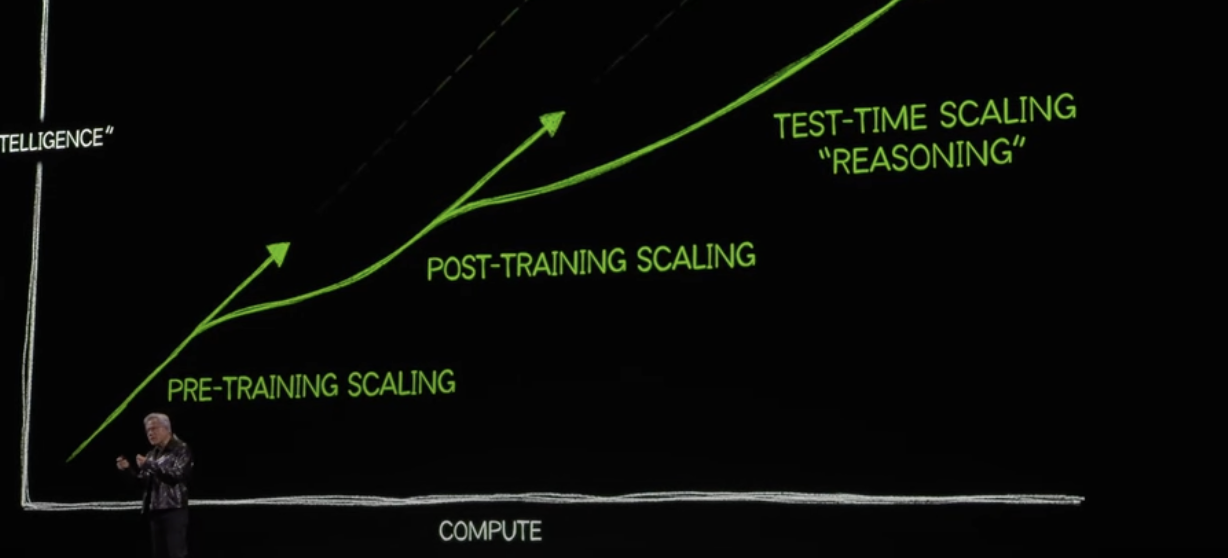
On the other hand, Neural Scaling Law defines the relationship between data set size, compute power, model size, and model performance. In theory, having a larger dataset, more model parameters, and more computing power should improve performance predictably. There are limits, however. Which means we may hit a point of diminishing returns. But one way to interpret that is that by having more data, the operating costs of inference can be lowered.
But if you think you can get away with just one box, let’s listen to what Mark Zuckerberg had to say on processing at their scale:
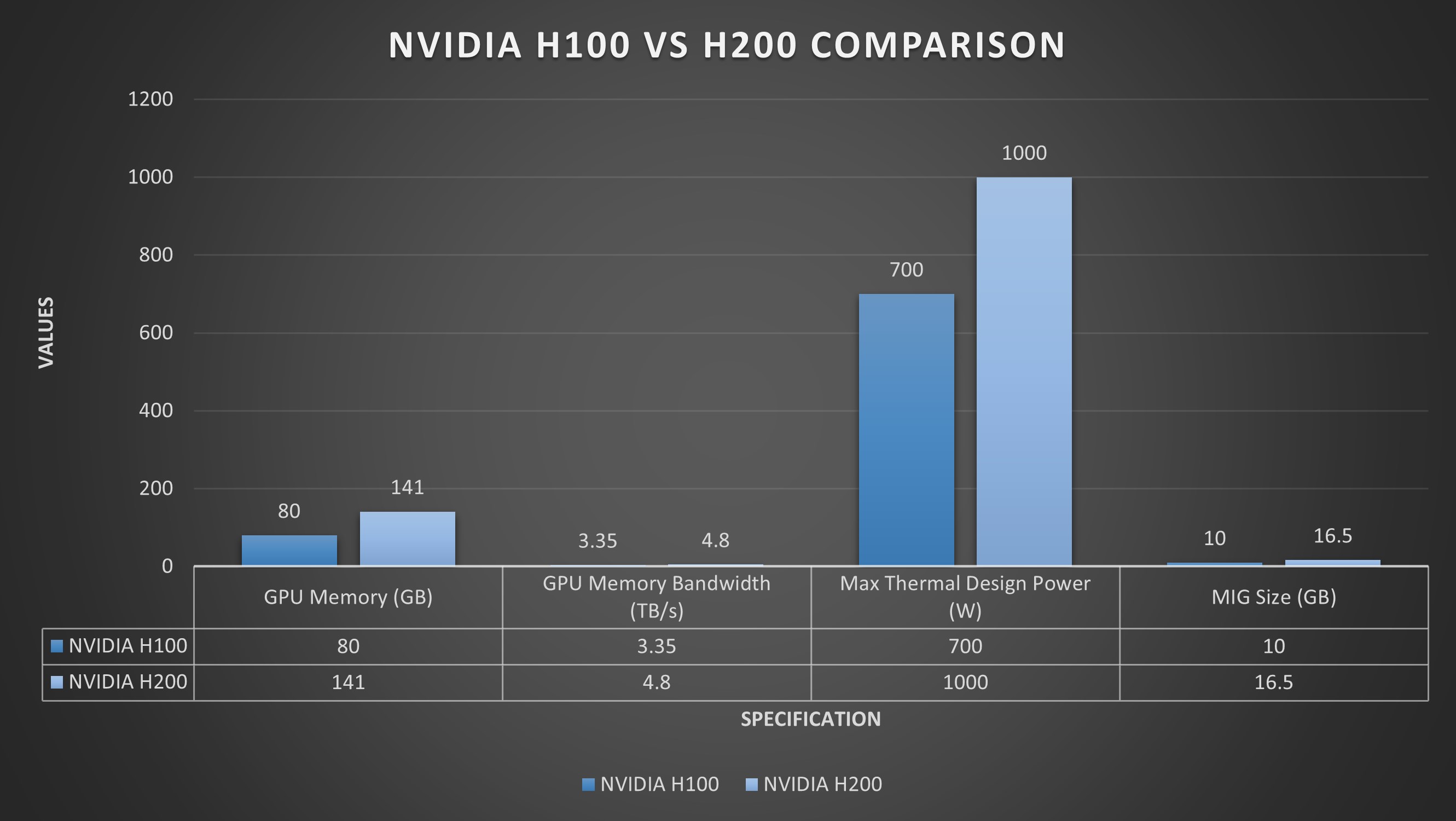
“We are building an absolutely massive amount of infrastructure to support this by the end of this year. We will have around 350,000 Nvidia H100 or around 600,000 H100 equivalents of compute if you include other GPUs,” Zuckerberg said.
Building, powering, and cooling these devices uses a large amount of resources, including:
You can save time and effort by using a technique called distillation, where you transfer the knowledge from a general-purpose model to a smaller, compressed model. Reportedly, DeepSeek’s R1 model was trained by distilling existing Foundation Models, like Meta’s Llama at vastly reduced costs:
However, that often-cited $5.6M number excluded a few other expenses:
Assuming the rental price of the H800 GPU is $2 per GPU hour, our total training costs amount to only $5.576M. Note that the aforementioned costs include only the official training of DeepSeek-V3, excluding the costs associated with prior research and ablation experiments on architectures, algorithms, or data.
Either way, post-training, including Reinforcement Learning (RL), is critical to improving the quality of the system:
[ THIS SECTION NEEDS REVISING TO SHOW ADS FOR EXPERTS AND RL PROCESSES FROM ARTICLE ]
RL and its counterpart, Reinforcement Learning from Human Feedback (RLHF), enable models to improve themselves by humans scoring and teaching them how to perform better. The rating process can be impacted by the thumbs-up/thumbs-down operation that beings with opposable thumbs are uniquely qualified to provide. But Human Feedback is expensive, requiring hiring, training, and validation, especially at scale (thousands or millions of iterations).
[ INSERT AD FOR HIRING EXPERTS ]
A clever, cost-cutting measure was therefore devised, where LLMs would gauge how well other LLMs were performing tasks. This way, an LLM can nudge another LLM back toward solving a given problem.
Problem solved! Except that negates the whole Human Feedback part of the process. We’re back onto RLWPHF (Reinforcement Learning Without Pesky Human Feedback), which is a little like the Blind men and Elephant parable.
We’re here to discuss costs, so let us acknowledge that Reinforcement Learning, without human input, offers post-training cost-effectiveness, leading to a capability explosion. But that can come at a degradation in… (checks notes) accuracy and correctness.
Deployment
When the model is ready, we can now enter the realm of Deployment. This is much like pushing an App onto an App Store. At scale, this requires multiple large-scale data centers, located as close to customers as possible to minimize network latency.
Unlike training costs, the cost of inference has no upper bound. It scales up with the number of users, the workload, and the flexibility of the infrastructure in terms of demand-based scaling.
Entertainingly, if your users are polite and were raised to say please and thank you to inanimate machines, it costs the companies more in processing those words (which they then have to skip while looking for User Intent).
One way to reduce inference runtime costs is to optimize each step, starting with splitting user-input into bits (aka tokenizing). This is an area where replacing one module, for example, OpenAI’s BPE TikToken Tokenizer with, say TokenDagger could yield significant savings:
There are othertechniques, but these may require significant changes to underlying architectures. Hardware vendors like NVIDIA would rather sell larger, more powerful hardware.
ROI: 3 in 4 organizations (74%) are currently seeing ROI from their gen AI investments.
Annual revenue increase: 86% of organizations using gen AI in production and seeing revenue growth estimate 6% or more gains to overall annual company revenue.
Accelerated time-to-value: 84% of organizations successfully transform a gen AI use case idea into production within six months. Once in production, organizations report an increase in annual revenue directly attributed to gen AI in 12 or more months.
They also go on to claim in the section on The Business Benefits of gen AI:
Productivity: 45% of organizations that report improved productivity indicate employee productivity has at least doubled as a result of gen AI.
Business growth: 63% of organizations have experienced business growth as a result of gen AI solutions.
User experience: 85% of organizations that report an improved user experience have seen increased user engagement, and 80% report improved user satisfaction due to gen AI
Security: 56% of organizations report improvements to their security posture. Of these, 82% report an improved ability to identify threats and 71% see a reduction in time to resolution.
Despite $30–40 billion in enterprise investment into GenAI, this report uncovers a surprising result in that 95% of organizations are getting zero return. The outcomes are so starkly divided across both buyers (enterprises, mid-market, SMBs) and builders (startups, vendors, consultancies) that we call it the GenAI Divide. Just 5% of integrated AI pilots are extracting millions in value, while the vast majority remain stuck with no measurable P&L impact.
…
The core barrier to scaling is not infrastructure, regulation, or talent. It is learning. Most GenAI systems do not retain feedback, adapt to context, or improve over time.
They also point out problems going from pilot projects to production:
The GenAI Divide is starkest in deployment rates, only 5% of custom enterprise AI tools reach production. Chatbots succeed because they’re easy to try and flexible, but fail in critical workflows due to lack of memory and customization. This fundamental gap explains why most organizations remain on the wrong side of the divide. Our research reveals a steep drop-off between investigations of GenAI adoption tools and pilots and actual implementations, with significant variation between generic and custom solutions.
This implies that there is much work to be done to go from lab to production and from deployment to a net-positive ROI. We’ll address the revenue side later, but to address costs, we should highlight the best ways to…
Reducing Costs
Whereas training costs can be constrained by the resources you are willing to allocate to the problem, inference / operating costs can grow, spike, and continue to increase with every user, potentially growing infinitely.
There are many ways to plan ahead, to reduce model size, and inference requirements, using techniques such as:
Mixture of Experts (MoE): use a gating router to select part of a model (i.e., expert) that should be activated for an input, then combine the results at the end. Very efficient for inference.
Chain of Experts (CoE): implement sequential communication between experts – more efficient than MoE.
HyperParameter Tuning: tweak parameters to help speed up training, e.g., learning rate or batch size.
Fine-tuning: adapt pre-trained models for specific tasks, similar to Transfer Learning.
Transfer Learning: Knowledge from solving one problem helps solve related issues.
Pruning: Remove unnecessary neural network connections or those that contribute little to the output.
Quantization: Reduce the precision of the parameters, e.g., from 32-bit floating point to 8 or 16-bit integers.
Few-Shot and Zero-Shot Learning: learn from a few (or no) examples to handle simple tasks.
Distillation: Transfer knowledge from a larger model to a smaller model.
Noise Reduction: remove irrelevant data up-front.
Neural Architecture Search (NAS): Dynamically adjusting mix of CPU, GPU, or NPU allocations.
L1 and L2 Regularization: Add constraints to prevent over-fitting and under-fitting.
Dropout: randomly deactivating neurons.
Weight Sharing: decreasing parameter count, lowering memory footprint, and computational load during prediction.
Huffman encoding: reduces memory and bandwidth use by shrinking the size of model weights and data structures like the Key-Value cache.
Multi-Token Prediction (MTP): models trained to predict multiple future tokens allow for faster results during inference through speculative decoding.
One of the most important ways to reduce cloud inference cost is to have a Dynamic Inference Router that sends user requests to the right model, best suited to handle the request. Part of that calculation may well be choosing the lowest cost process.
In a compelling post rife with back-of-the-napkin estimates, the case was made that the cost of inference has dropped so much that, given what AI vendors charge their paying customers, the profit margins may well be astronomically high.
It implies that the main reason these companies are showing such high burn rates is due to the cost of data acquisition, infrastructure, staffing, and training their next-generation models.
Fenghui: Well, one thing that’s super important is the cost. We’re trying to make inference as affordable as possible. Let’s say we’re trying to make a smaller, more affordable version of Gemini available to people. We would work on the model’s inference to find ways to change the computation paradigm, or the code that makes up the model, without changing the semantics, or the principal task it’s supposed to do, in order to reduce the cost. It’s basically making a smaller, more efficient version of the model so more people can access its capabilities.
How do we bring the cost down?
Fenghui: One way is to optimize the hardware. That’s why we have Ironwood coming out this year. It’s optimized for inference because of its inference-first design: more compute power and memory, and optimization for certain numeric types. Software-wise, we’re improving our compilers and our frameworks. Over time, we want AI inference to be more efficient. We want better quality, but we want a smaller footprint that costs less to be helpful.
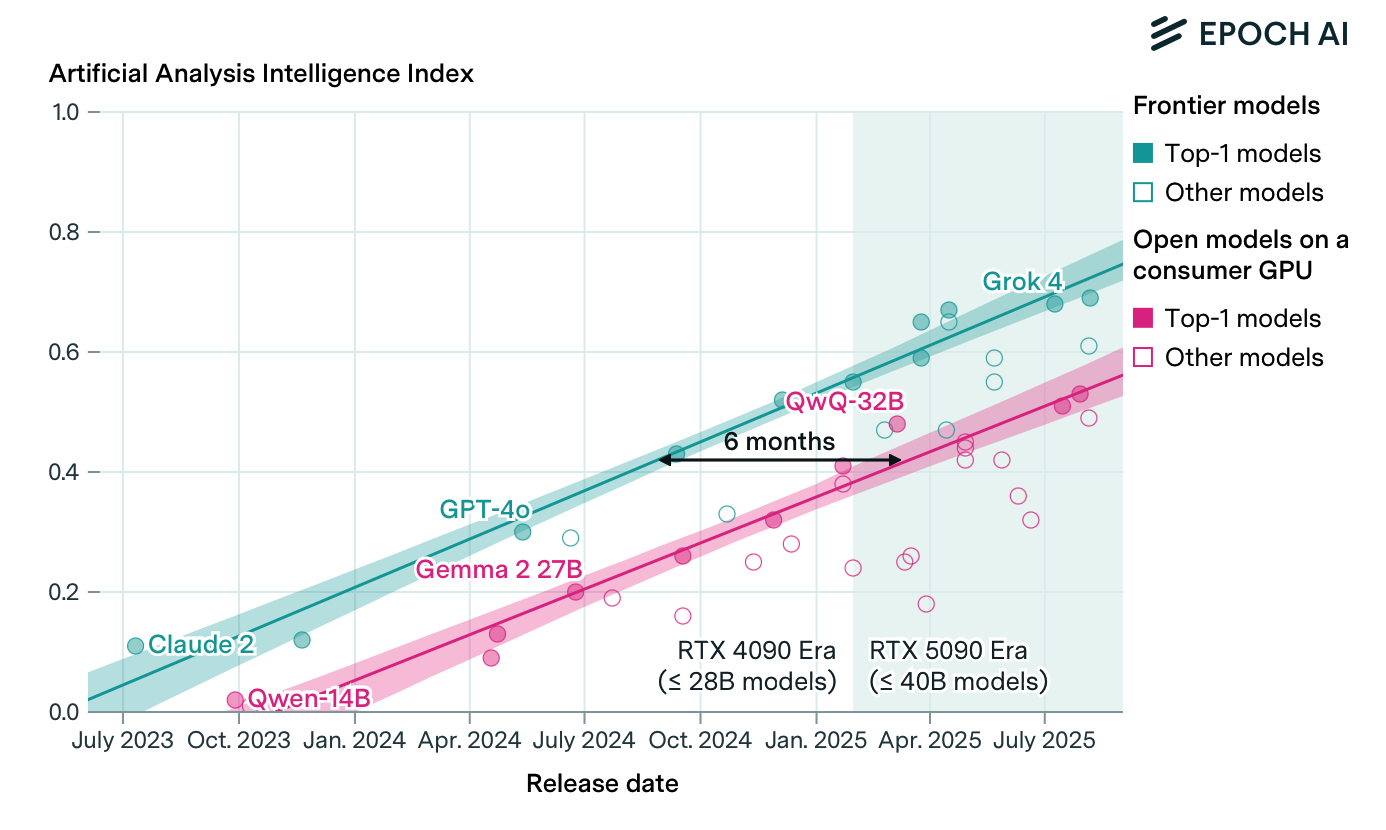
There are predictions that the time gap between inference models running on heavy iron vs. consumer-grade GPUs has shrunk:
Using a single top-of-the-line gaming GPU like NVIDIA’s RTX 5090 (under $2500), anyone can locally run models matching the absolute frontier of LLM performance from just 6 to 12 months ago. This lag is consistent with our previous estimate of a 5 to 22 month gap for open-weight models of any size.
In subsequent sections, we will examine how inference is migrating to on-device hardware.
This will create a significant shift in runtime expenses, putting the burden on customer hardware. It will directly impact the profitability and long-term survival of the industry, and may slow down the profligate spending.