
Software vs. Hardware

On top of all the costs we listed – data acquisition, training, distilling, and runtime inference – when it comes to standalone assistants, there are a few extra ones to throw onto the heap:
- Voice-to-Text
- Text-to-Speech
- Remote MCP calls
- Agentic Workflows, and
- Third-party integrations (shopping, weather, traffic, Smart Home)
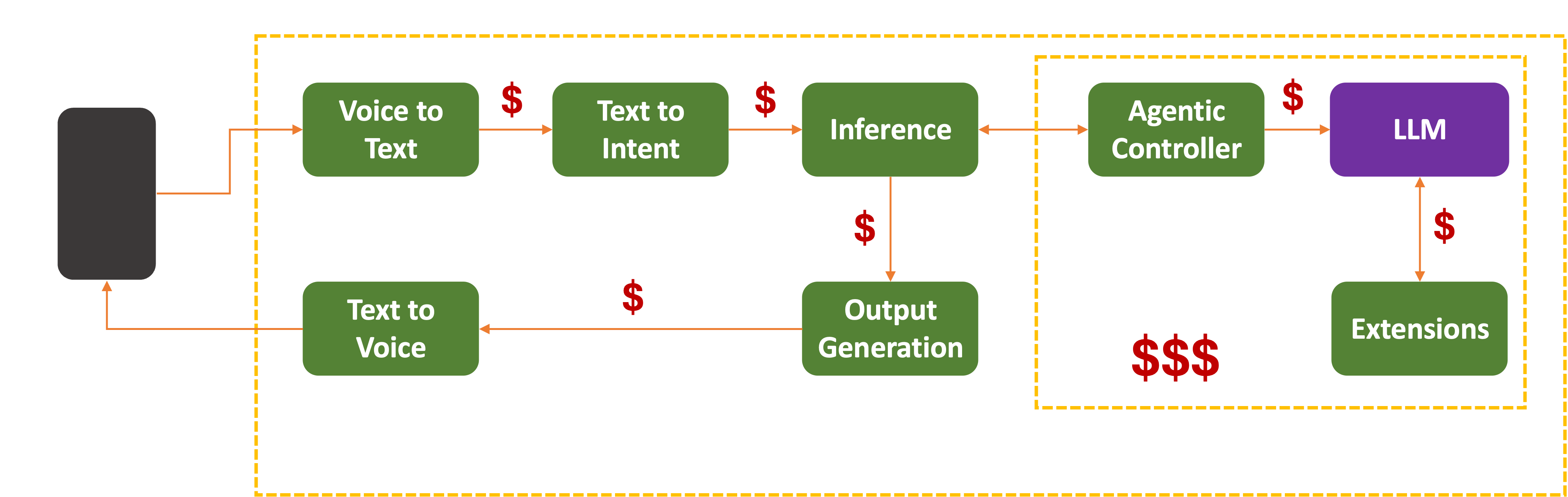
Those can add up too, especially if the Assistant devices have little on-board processing power and rely on the cloud for most of their functionality.
In that case, even small optimizations such as Voice Activity Detection can shave off significant savings at scale. Cloud-based LLM inference is expensive. There is no way around it.
Unless…
On-Device/Edge Inference
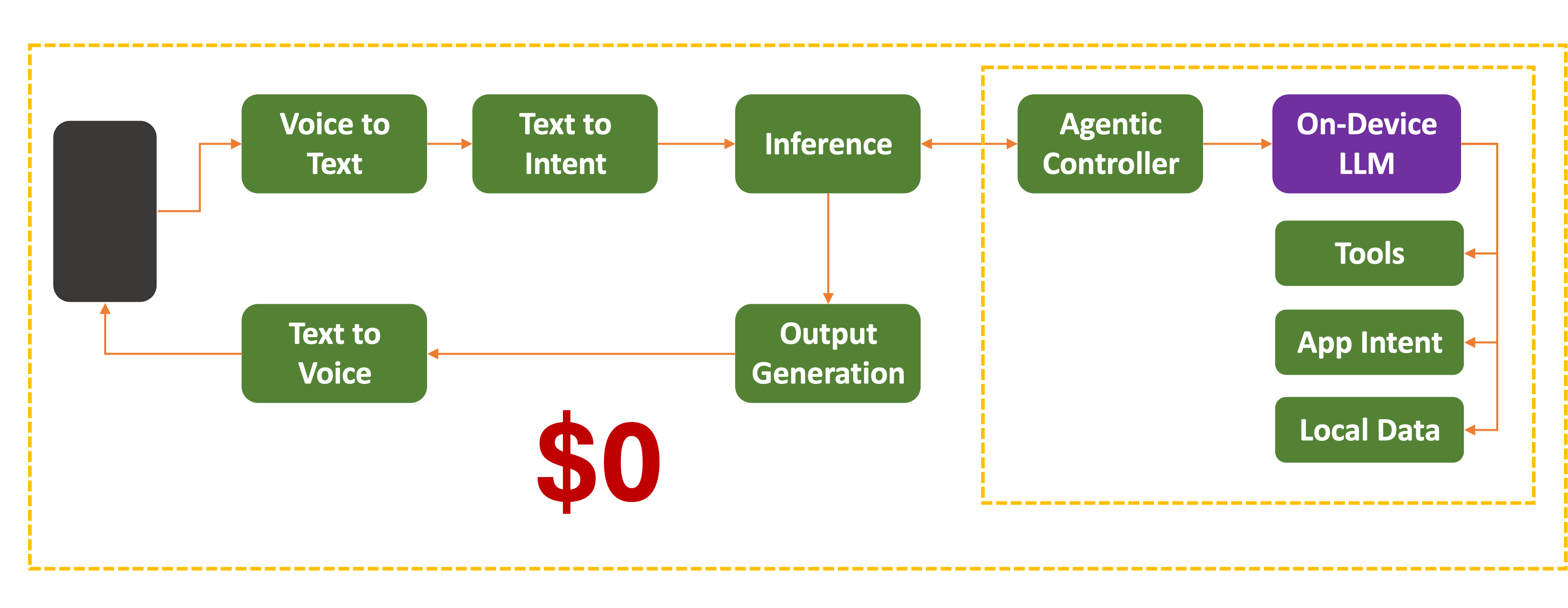
What if you tan some (or all) inference on a device itself? The less you send to the cloud, the lower the cost of networking, centralized power consumption, cooling, and all that we have covered above.
Propositio: The operating cost of running an agent on-device is incomparably less than running on the cloud.
But that only works if there is enough processing power on a device. This means beefier processors, larger storage, and more high-speed memory. The baseline $30 home AI Assistant is not designed for this.
The most common technique for squeezing down the storage and memory requirements of a model is Quantization:
Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32).
Reducing the number of bits means the resulting model requires less memory storage, consumes less energy (in theory), and operations like matrix multiplication can be performed much faster with integer arithmetic. It also allows to run models on embedded devices, which sometimes only support integer data types.
This reduction carries a risk:
We reveal that widely used quantization methods can be exploited to produce a harmful quantized LLM, even though the full-precision counterpart appears benign, potentially tricking users into deploying the malicious quantized model.
…
In practice, the adversary could host the resulting full-precision model on an LLM community hub such as Hugging Face, exposing millions of users to the threat of deploying its malicious quantized version on their devices.
At current prices fully running on-device inference with voice processing and generation and a moderate sized LLM is possible, albeit expensive. Advanced hardware, memory, and storage required may push the Bill Of Material (BOM) toward the higher range of what is common in consumer-grade devices. The cost will undoubtedly come down once these are commodotized.
Here is a sampling of PCs and laptops with NPU/TPU support:
| Manufacturer | Model | NPU/TPU type | Published NPU speed | Typical price (US) |
|---|---|---|---|---|
| Microsoft | Surface Laptop (7th gen, Copilot+ PC, 13.8″/15″) | Qualcomm Hexagon NPU (Snapdragon X Elite/Plus) | 45 TOPS | $1,099–$2,399. (Microsoft, The Official Microsoft Blog) |
| Samsung | Galaxy Book4 Edge (14/16) | Qualcomm Hexagon NPU (Snapdragon X Elite/Plus) | 45 TOPS | From $999 (14″). (Samsung, The Official Microsoft Blog) |
| HP | OmniBook X 14 | Qualcomm Hexagon NPU (Snapdragon X Elite/Plus) | 45 TOPS | Varies by config (see HP store). (HP, The Official Microsoft Blog) |
| Lenovo | Yoga Slim 7x (Gen 9, 14″) | Qualcomm Hexagon NPU (Snapdragon X Elite) | 45 TOPS | Varies by config (see Lenovo). (Lenovo, The Official Microsoft Blog) |
| Microsoft | Surface Pro (11th ed., Copilot+ PC, 13″) | Qualcomm Hexagon NPU (Snapdragon X Elite/Plus) | 45 TOPS | Varies by config (consumer & business). (Microsoft, Source) |
| Acer | Swift 14 AI (Lunar Lake) | Intel NPU 2.0 | Up to 48 TOPS (NPU) | Varies by config (Acer). |
| Various | Intel Core Ultra (Meteor Lake) laptops (e.g., XPS 13, Zenbook S 13, Swift Go 14) | Intel NPU 1.0 | ~11 TOPS (NPU) | Typically $999–$1,699 depending on model. (AMD) |
| Apple | MacBook Pro 14″ (M3) | Apple Neural Engine | ~18 TOPS (ANE) | From $1,599 (Apple Store). (Wikipedia) |
| Apple | iMac 24″ (M4, 2024 refresh) | Apple Neural Engine | 38 TOPS (ANE) | From typical iMac pricing; varies by config. (Apple) |
| Apple | MacBook Air (M4, 2025) | Apple Neural Engine | 38 TOPS (ANE) | From typical MBA pricing; varies by config. (Apple) |
Here are Mobile Phones with on-device processing capabilities:
| Manufacturer | Model | SoC / NPU/TPU | Published NPU/TPU speed | Typical price (US) |
|---|---|---|---|---|
| Apple | iPhone 15 Pro / Pro Max | A17 Pro / Apple Neural Engine | 35 TOPS | $999–$1,199. (Intel Download Center, Apple) |
| Apple | iPhone 15 / 15 Plus | A16 Bionic / Apple Neural Engine | ~17 TOPS (published in tech refs) | From $699. (Wikipedia, Apple) |
| Apple | iPhone 16 Pro / Pro Max | A18 Pro / Apple Neural Engine | Not disclosed by Apple (faster than prior gen) | From $999. (Apple) |
| Apple | iPhone 16 / 16 Plus | A18 / Apple Neural Engine | Not disclosed by Apple (faster than A16) | Pricing varies by storage; see Apple. (Apple) |
| Pixel 8 Pro | Tensor G3 / Google TPU | Not publicly disclosed by Google | ~$999 (Google Store). (Google Store) | |
| Samsung | Galaxy S24 Ultra (US) | Snapdragon 8 Gen 3 / Hexagon NPU | Not publicly disclosed by Qualcomm | ~$1,019+ (Samsung). (Samsung) |
| OnePlus | OnePlus 12 | Snapdragon 8 Gen 3 / Hexagon NPU | Not publicly disclosed by Qualcomm | $899–$999. (OnePlus) |
| Samsung | Galaxy S24 / S24+ | Snapdragon 8 Gen 3 (US) or Exynos 2400 (intl) | Not publicly disclosed by Qualcomm/Samsung | Typical $799–$999. (Samsung) |
| Sony | Xperia 1 VI | Snapdragon 8 Gen 3 / Hexagon NPU | Not publicly disclosed by Qualcomm | Price varies by region. (Vendor pricing) |
| ASUS | ROG Phone 8 / 8 Pro | Snapdragon 8 Gen 3 / Hexagon NPU | Not publicly disclosed by Qualcomm | Price varies by config. (Vendor pricing) |
For embeddable or edge devices:
| Manufacturer | Device | NPU/TPU type | Published speed | Typical price (US) |
|---|---|---|---|---|
| NVIDIA | Jetson Orin Nano Dev Kit | Jetson Orin NPU/GPU (Edge AI SoC) | 20 TOPS (INT8; higher “sparse TOPS” also cited) | ≈$499. (NVIDIA Developer) |
| NVIDIA | Jetson Orin NX Dev Kit | Jetson Orin NPU/GPU | Up to 70 TOPS | ≈$599–$699. (Amazon) |
| NVIDIA | Jetson AGX Orin Dev Kit | Jetson Orin NPU/GPU | Up to 275 TOPS | ≈$1,999. (NVIDIA) |
| Google Coral | USB Accelerator | Edge TPU | 4 TOPS | ≈$59–$75. (MSI Store) |
| Google Coral | Dev Board | Edge TPU | 4 TOPS | ≈$129–$150. (Acer United States) |
| Google Coral | Dev Board Mini | Edge TPU | 4 TOPS | ≈$99–$115. (Dell) |
| Hailo | Hailo-8 M.2/mini-PCIe module | Hailo-8 | 26 TOPS | Module pricing varies (OEM). (Hailo) |
| Raspberry Pi + Hailo | Raspberry Pi AI Kit | Hailo-8L | 13 TOPS | ≈$70–$80. (Amazon) |
| Intel | Neural Compute Stick 2 | Intel Myriad X VPU | ~1 TOPS | ≈$99. (Intel Community) |
| Radxa | ROCK 5B SBC (RK3588) | Rockchip NPU | Up to 6 TOPS | ~$175–$289 depending on RAM. (Radxa, eBay, Amazon) |
| Luxonis | OAK-D (DepthAI family) | Intel Myriad X VPU | ~1 TOPS (Myriad X DNN) | ~$199–$349 depending on model. (Luxonis, Intel) |
| NXP | i.MX 8M Plus EVK | Integrated NPU | Up to 2.3 TOPS | ≈$259–$633 (varies by kit/vendor). (NXP Semiconductors, TechNexion, Toradex) |
[ ARM just announced embeddable NPUs as part of their ARM IP so the number will no doubt go up ]
Smart Speakers
A significant number of current users will not be in posession of devices that can run on-device inference. This is a transitional phase, as more capable devices make their way into customer hands. Product Managers have to face difficult product choices in the near-term:
- Focus on only new users with the latest devices. This cuts off owners of older devices.
- Forget on-device. Just do it all on the cloud. Potentially uncapped inference fees.
- Create a hybrid service that works under both scenarios.
- Amazon’s Alexa+ service has gone with #1, by limiting the service (at least for now, to higher end models like Echo Show 8, 15 or 21).
- Google Nest devices do have local TPUs, but likely not enough capacity and storage to run everything locally. Google is rolling out their Gemini LLM model to run on existing models. These appear to be Hybrid models.
- Apple’s Siri 1.0 is clearly #2, even though Apple’s new flagship devices have plenty of local processing capcity.
- Siri 2.0 is going with #3, which is probably why it’s delayed.
All other assistants are waiting to see which version makes more sense. From a financial point of view, on-device makes the most financial sense. Just run it all on-device. This has so many other advantages:
- User privacy (data doesn’t leave the device). This also helps with GDPR/CCPA and other data sovereignty issues.
- Lower response latency. Come on, who doesn’t love that?
- Less need for those expensive data centers, if they’re running inference. They’ll still need them to do all the heavy training, but that cost isn’t infinitely scaling like inference.
- For the many users who are on metered plans, less network traffic.
- Force users to upgrade to the latest, greatest flagship device.
From a device manufacturer’s point of view this should be a no-brainer. So why isn’t everyone running on-device?
On-Device is not Panacea
To run inference on-device, the user needs to have enough:
- Flash storage: for the LLM. Even small ones run multi-gigabytes.
- RAM: 8 or 16GB minimum.
- Shared processor memory (GPU/NPU/TPU).
- Power: running multiple threads of execution could quickly drain the battery and generate heat.
- Accuracy: A reduction in size also comes with a potential reduction in capability and accuracy.
For a home AI Assistant, however, power is less of a concern, unless it starts racking up noticable amount of usage and it shows up on their home electricity bill.
Here is a sampling of models that (as of this writing) can potentially fit to run on-device:
| Name | Developer/Company | License | Mobile Compatible | Link | Features |
|---|---|---|---|---|---|
| BitNet b1.58 | Microsoft | MIT | CPU, edge devices | GitHub | 1.58-bit weights, CPU-optimized |
| Gemma 2B | Google DeepMind | Gemma Terms | Phone, tablets | HuggingFace | 2B params, built on Gemini |
| Gpt-oss-20b | OpenAI | Apache 2.0 | High-end devices (16GB RAM) | HuggingFace | 21B params, 128K context |
| Llama 3.1 8B | Meta | Llama 3.1 License | High-end devices | Meta AI | 8B params, 128K context |
| MiniCPM | OpenBMB/Tsinghua | Apache 2.0 | Phone, tablets | GitHub | 1B-4B params, competitive with 7B models |
| Mistral 7B | Mistral AI | Apache 2.0 | High-end mobile | Mistral AI | 7B params, 8K context |
| MobileLLM | Meta Research | Research only | Phone, embedded | Paper | 125M/350M |
| OpenELM | Apple | Apple Sample Code | iOS, embedded | Apple ML Research | 270M/450M/1.1B/3B |
| Phi-3 Mini | Microsoft | MIT | Phone, embedded | HuggingFace | 3.8B params, 4K/128K context |
| Qwen3 0.6B | Alibaba Cloud | Apache 2.0 | Mobile, IoT | HuggingFace | 0.6B params, 32K context |
| SmolLM v3 | Hugging Face | Apache 2.0 | Mobile, IoT | HuggingFace | 3B, 128K context |
| SmolLM | Hugging Face | Apache 2.0 | Mobile, IoT | HuggingFace | 135M/360M/1.7B, 8K context |
| StableLM Zephyr 3B | Stability AI | Non-commercial | Edge devices | Stability AI | 3B params, 4K context |
DIY
If you want to train your own small model, a good starting point is nanotron for pre-processing, then datatrove to filter and de-dupe, and lighteval to evaluate the generated output.
Once trained, you can run the model locally using any of:
You can also put a nice web-based chat interface in front of your model using Open WebUI
What about Google?
From a functional point of view, Google and Apple devices are similar. Apple has the new Foundation Model frameworks. Google has had MediaPipe LLM Inference API. For the sake of brevity, I’ve focused on Apple, but to stay in the good graces of my Google friends, I am duty-bound to point out that Google’s got all the same features (and problems).

Google actually goes one step further, by generously offering MediaPipe running via WASM inside web browsers, a fact that I am taking advantage of in the Project Mango gaming engine.
However, Google will be torn between the Scylla and Charybdis of whether to support on-device inference (and save costs), or collect user-data to train data models.
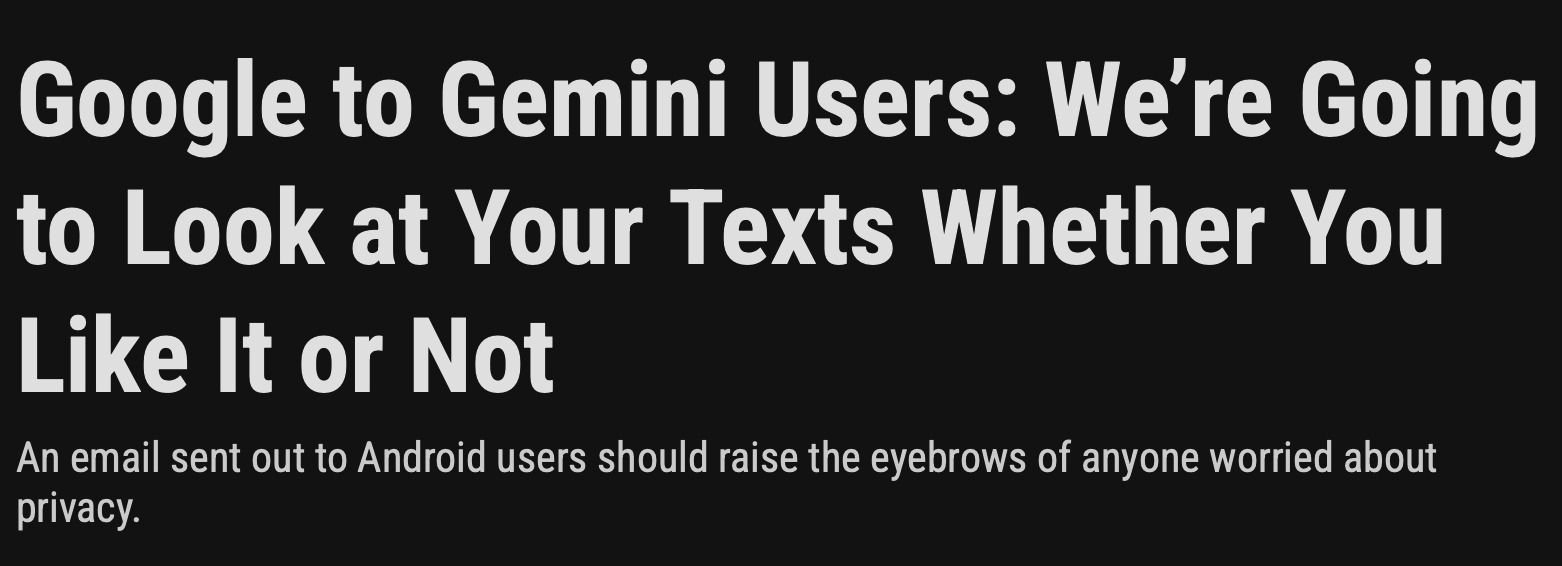
Based on recent reports, it looks like they have chosen to do both.