
Extensions, as we covered in the last section, are a good way to break out of a closed, monolithic LLM. There are many ways to add them in. The architecture of AI/ML systems has a long way to go before it becomes self-referential, like a human mind.
But we have what we have. Let’s take a look at some of the nuts and bolts and think about how they could be made better, or at least, more open-ended and functional.
In that vein, we’ll end with a whole other way that will make your toes curl.
Doin’ the RAG
First you get down on your knees
Fiddle with your rosaries
Bow your head with great respect
And genuflect, genuflect, genuflect!
Do whatever steps you want if
You have cleared them with the pontiff
Everybody say his own
Kyrie eleison
Doin’ the Vatican Rag.
With the first generation of generative AI models, enterprise users had no way to access internal data, limiting their utility.
In 2020, researchers from Facebook AI, University College London, and NYU published a seminal paper on Retrieval-Augmented Generation (RAG). RAG allowed LLMs to access external data sources. If you followed the previous section on Extensions, this was analogous to
But building RAGs required a certain level of specialized knowledge and were difficult to add to commercial LLM services.
Realizing this shortcoming, OpenAI came up with the concept of a Function Calling model. If you were using the OpenAPI client SDK code, you could provide local functions that the SDK could register with OpenAI for your specific context.
If you asked ChatGPT to perform a task, say, look up stock data or the weather, it could try to answer through its own trained knowledge base. But it would soon realize that it lacked the information. It could try to look it up on the open web, but it was often unreliable or blocked by a paywall.
Instead, you could offer a private API to access stock and weather data. Now, it could call back your own functions, pass its parameters, have
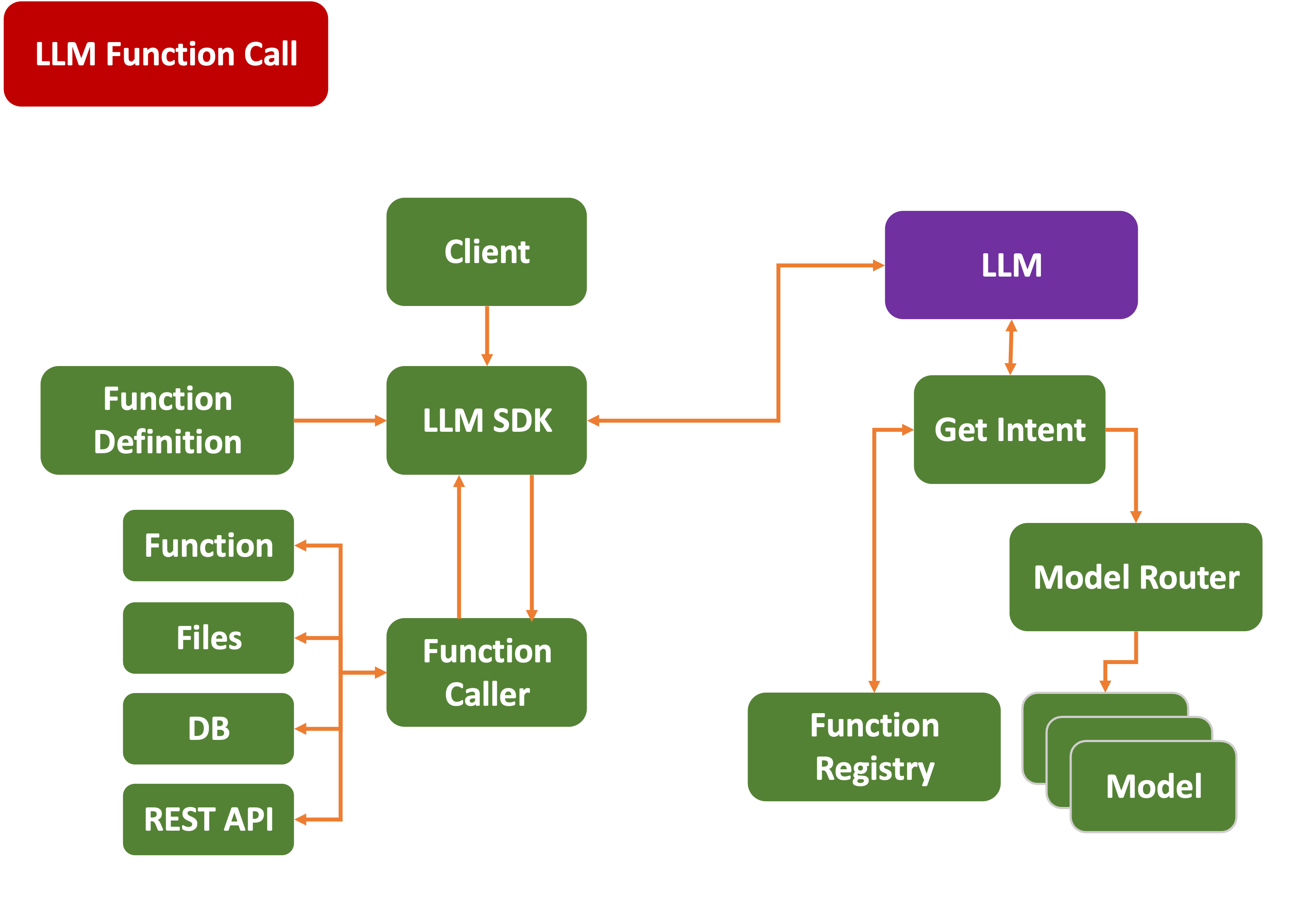
The LLM could then interpret and process this and return it to you as if it had invented it all by itself.
This had a few advantages:
- OpenAI
didn't have to pay for invoking all these remote APIs ($$$ saved, plus privacy, double-plus not making OpenAI a source for DDOS attacks) - You could use
private or paid services requiring API keys (which you would hold onto and use yourself) - Best part (for them):
OpenAPI collected a fee for all the token processing, coming and going.

That got you an answer that was augmented by your own sources’ data.
The problem was that it only worked inside OpenAI’s ecosystem, leaving out all the other competitors.
Enter…
Model Context Processor (MCP)
Not wanting to be left behind, Anthropic developed its own function-calling method. They called it Model Context Processor and open-sourced it in November 2024.
On its surface, it behaved much like the OpenAI function call model, but it had a few notable distinctions, including allowing support for LLMs running locally:
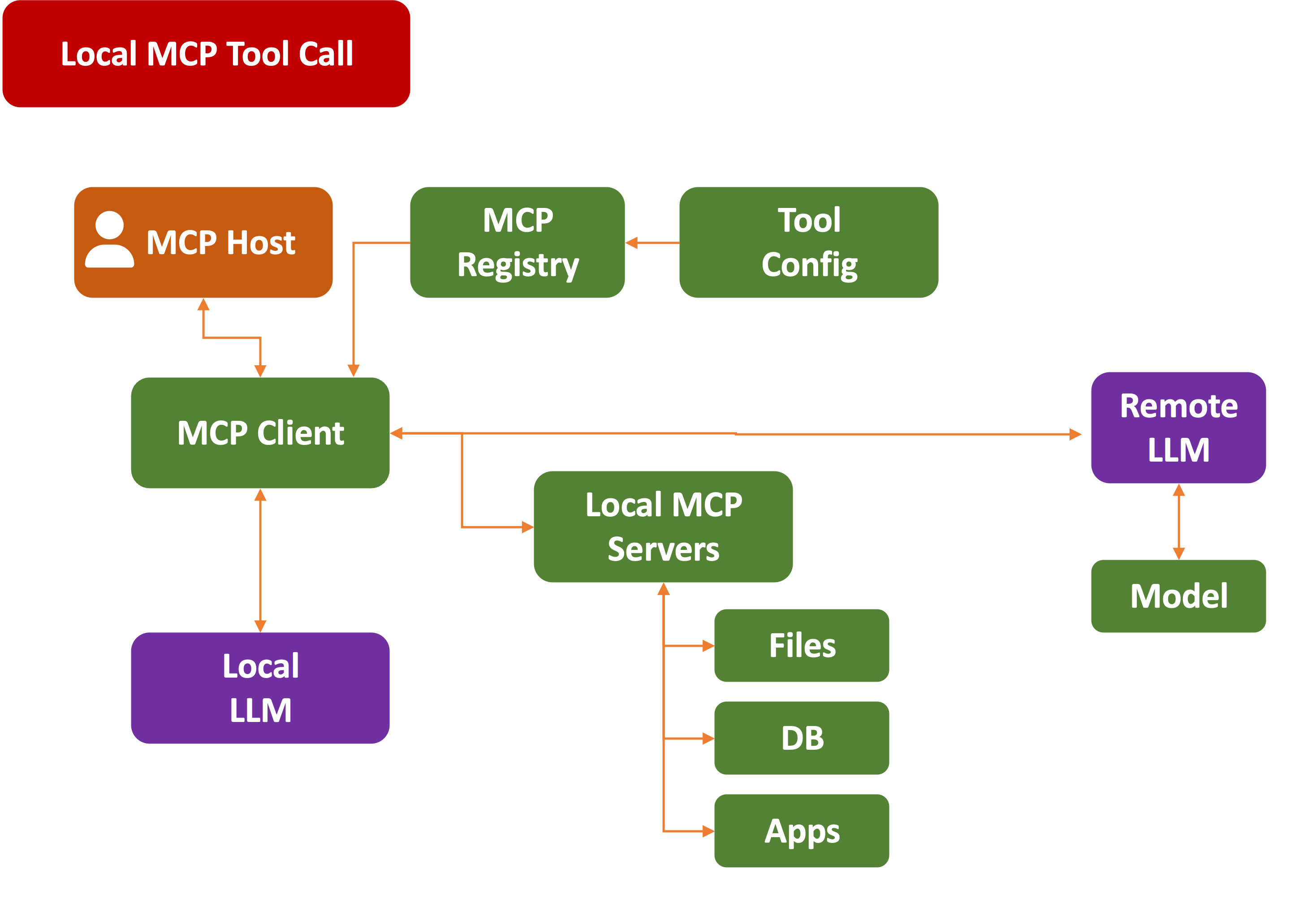
It also went several steps beyond just Tools and handled other abstractions, like:
-
Resources: this wraps any data explicitly offered by the MCP server to clients, including access to files, databases, APIs, live system data, screenshots, log files, etc.
-
Prompts: are reusable templates for standardized interactions. They can be shown to the user like pre-packaged macros, which they can invoke with a single command.
-
Roots: define the boundaries of where the LLM can ask the server to traverse. For example, a certain directory or service.
-
Sampling: ways for MCP servers to ask for LLM completions, or multi-step agent behavior. To be honest, as of this writing, this is a bit… waffly (technical term of art).
Another part unique to MCP was that it supported different Transports, including:
- stdio: Standard input and output streams. This allows a
command-line tool to run with the input and output piped in from some other process, pretty much how Unixshell scripts work. - Server-Sent Events (SSE): Used to maintain an
open stream between the server and client , but it had security problems and direct use has since been deprecated in favor of… - Streamable HTTP:
Bi-directional , allowing for both POST requests from client to server and SSE streams for server-to-client. This will enable you to send a command, then receive the results in small chunks instead of having to wait until everything is done.
# WebSocketsThere’s a well-known, two-way communication streaming protocol (IETF RFC6455: The WebSocket Protocol) that is supported by most languages, libraries, and browsers.
However, MCP designers opted for the SSE and Streamable HTTP transport model. Why?
This was asked during the 2025 MCP Developer’s Summit. They said they didn’t want to use WebSockets because it would require using asynchronous servers, which are a little more cumbersome to manage and (they said) would add complexity.
I strongly disagree. Websocket is being used in gaming, messaging, and anything real-time that can happen inside the browser. I am confident that WebSocket support will be added in a future version of the spec.
It will be absolutely necessary for situations where
externally generated events need to be handled by LLMs. That is one area that is woefully neglected by the AI Product community.
BTW, if you want a truly deep dive into how MCP works, this is worth a watch:
# Outstanding IssuesMCP Tools expand the capabilities of an AI model to answer questions beyond the model training data.
But how does the system decide
which tool to call?
- What if multiple tools use the same name?
- Or if a tool claiming to be a popular weather extension sends your credentials somewhere else?
- What if you had two tools enabled, both of which said they could get
weather data ? Who gets to decide?- What if one was free and the other required payment or had geographic usage restrictions, and another didn’t.
Would that make a difference? - Also, how many tools can you install and invoke simultaneously?
When asked, Anthropic folks recommended having a
registry layer to help find the right MCP tool. That sounded like kicking the can down the road.They also claimed they got Claude to work with
hundreds of tools. But they also said the more tools you used, the more likely it was to getconfused .

Remote MCP
Enterprise service companies can offer access to their services by hosting Remote MCP servers, which customers can use directly. This effectively turns their publicly facing APIs into embeddable one-stop SDKs for LLMs.
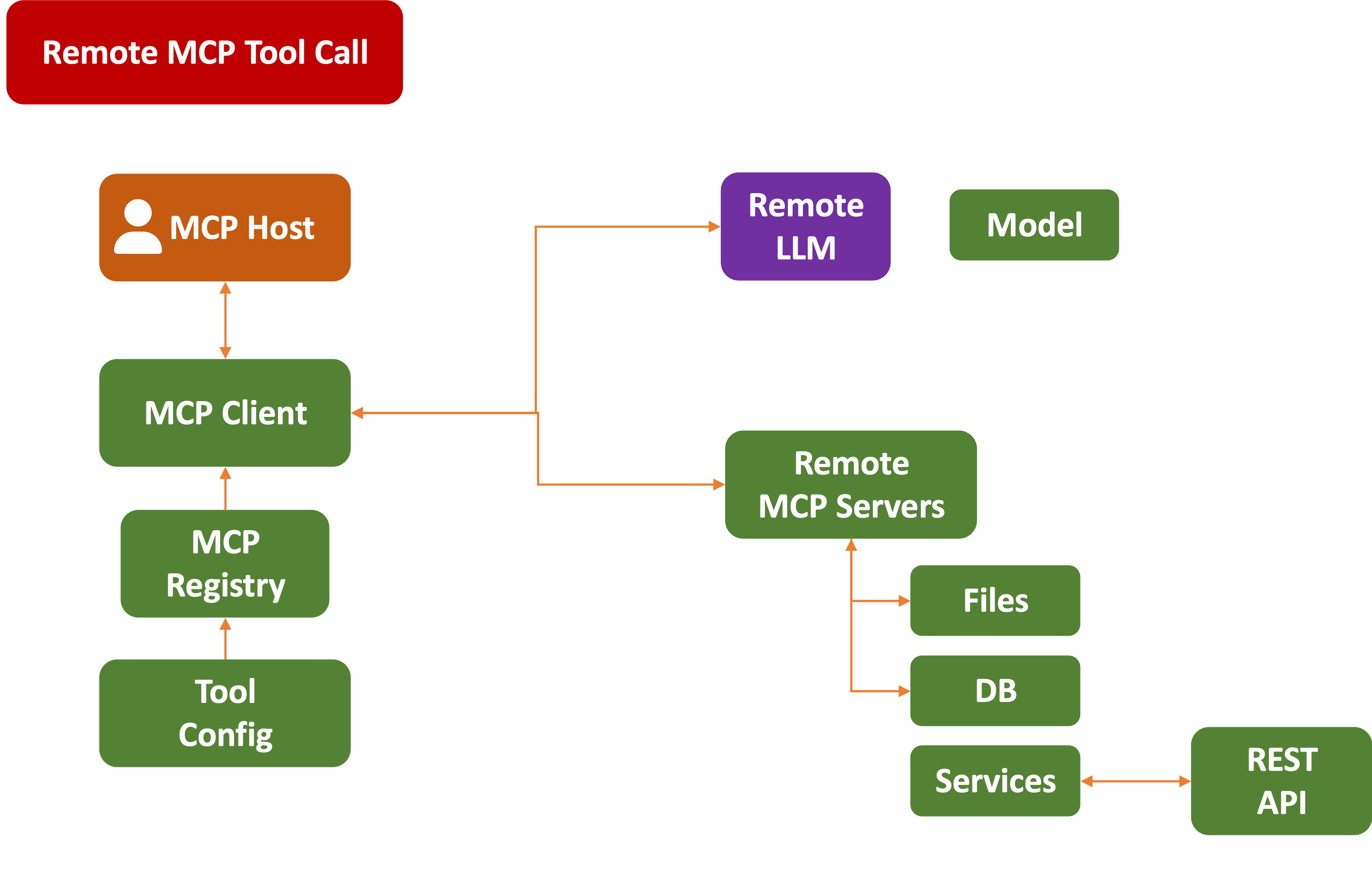
Cloud service providers (like AWS) not only offer MCP servers for their own services but also guidance on ways to build and deploy your own and to orchestrate them across different LLMs [Full Disclosure: used to work there, so I’m most familiar with their stack].
In the interest of fairness, here’s how to make remote MCP servers using other cloud providers:
Creating remote MCPs is pretty straightforward, very compute-intensive, and highly sticky. Once you’ve added them to your stack, it’s a heavy lift to get rid of them and go elsewhere, which is one reason why all cloud service providers are salivating at their prospect. At this point, any cloud service provider NOT offering their customers step-by-step MCP-hosting guides is
Fast Forward: AI + Tools at the Edge

You can run LLMs, MCPs, and RAGs on the cloud. But what if you didn’t want to? What if your data was proprietary and it couldn’t leave your network? Or you had actually done the math and calculated the token cost of sending everything to the cloud and back.
Should we go back to the days of servers running under people’s desks? Hasn’t the cloud taught us anything? You want me to drag out the Catechism on Capex vs. Opex?
The problem is, I don’t have to make the case. No less than lesser-known outfits like Microsoft and Apple are enabling running AI locally.
Let’s take a look.
Microsoft Local

At Build 2025, Microsoft announced a wide range of new services, most prominently focusing on AI, Agentic operations, and a most promising Windows AI Foundry (rebranded from Windows Copilot Library, AI frameworks–DirectML, and AI Toolkit for Visual Studio Code).
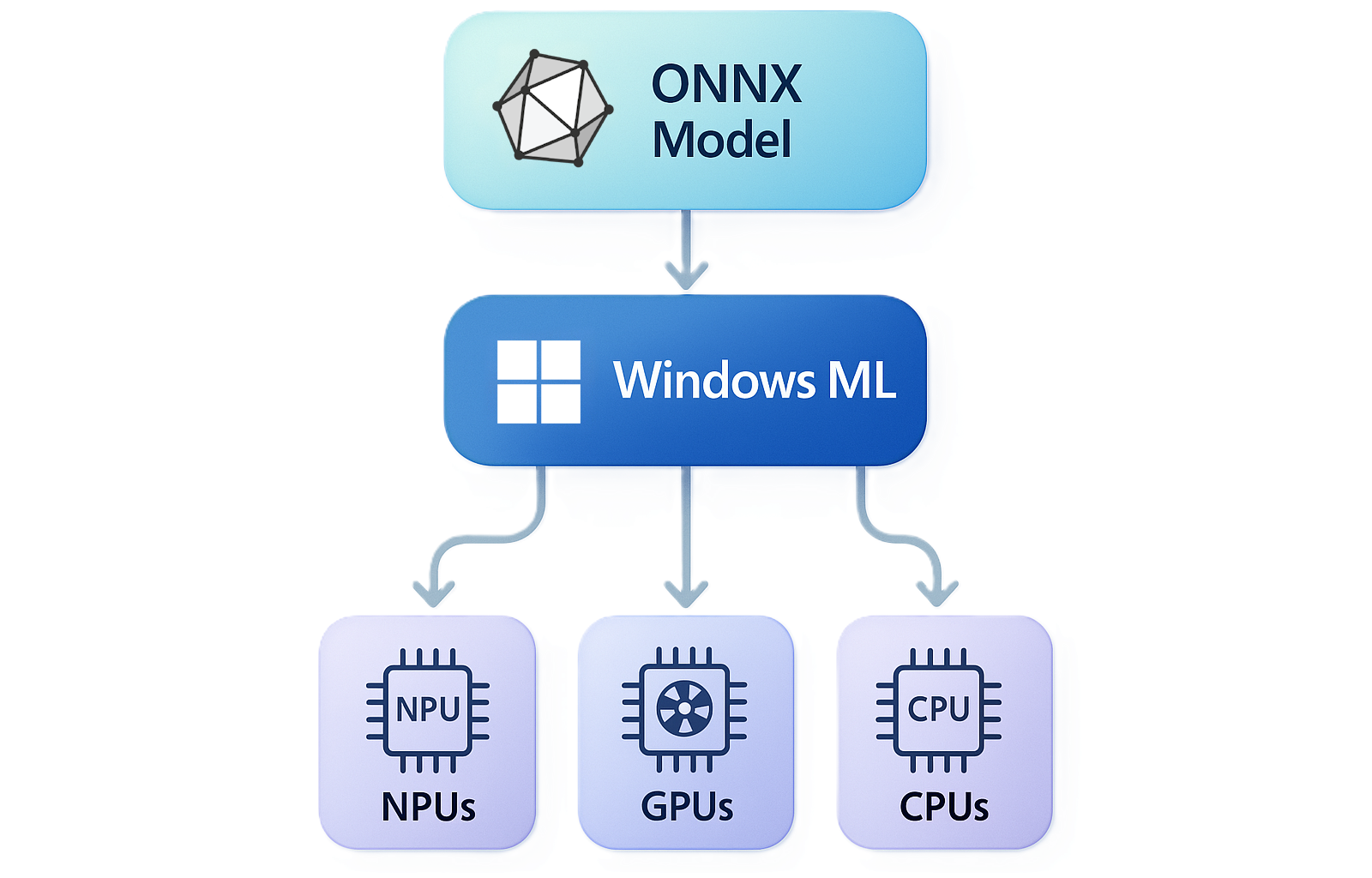
The cool part (IMO) was Windows ML, which provided a standard interface to running models locally, while adapting to whatever the system has available (NPU, GPU, or CPU), as well as Foundry Local
ONNX, in case you’re wondering, stands for Open Neural Network Exchange, which is a cross-platform, cross-language format that, along with its own runtime, is run by the Linux Foundation
# WebSocketsNot to be confused with ONNX, a phishing service of the same name that was busted by Microsoft’s Digital Crimes Unit, helping avoid confusion.
To get an early peek at AI running locally on your machine and the workflow, you can try it out on your Windows machine by building AI Dev Gallery from source, or downloading the binary.
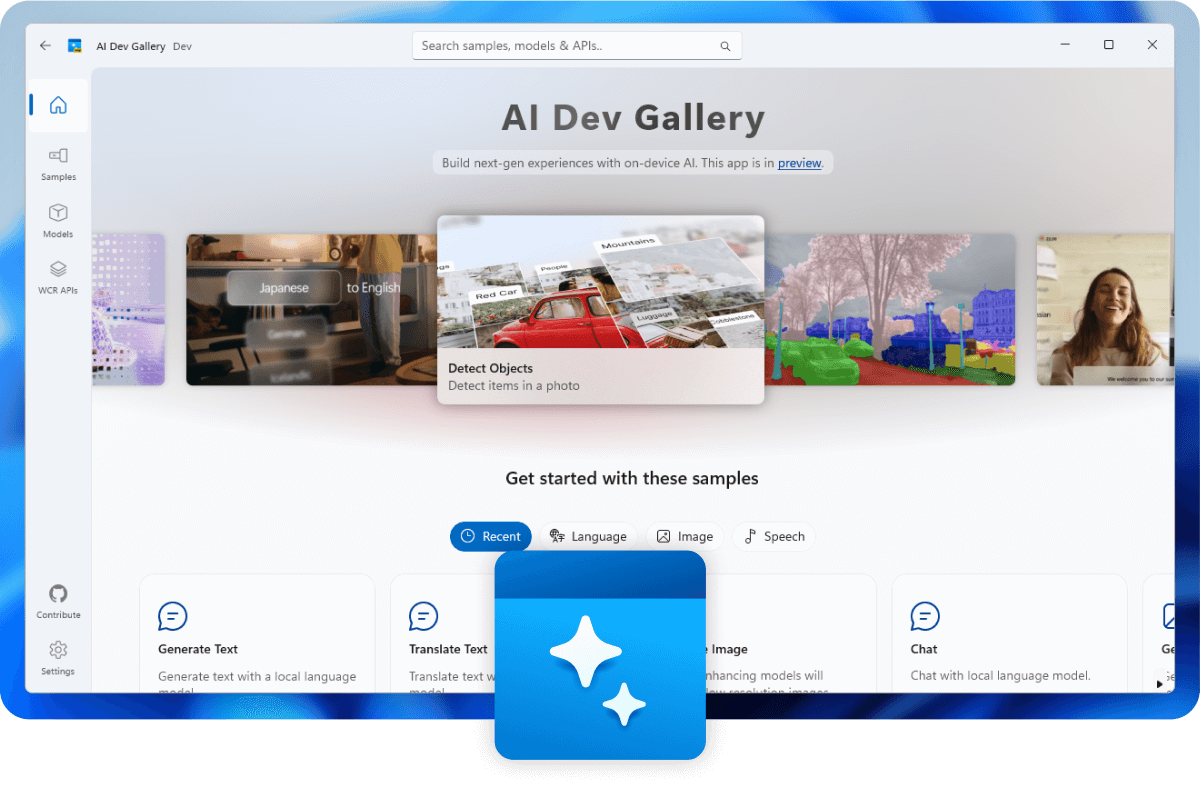
As a developer, you can invoke LLMs inside your apps, download and cache models appropriate to the user’s runtime device, and run MCP tools. All in all, a solid first pass.
Apple Local
At WWDC24, Apple announced plans to support On-Device and Server Foundation Models. These were not released until WWDC25, in June 2025.
The framework allows applications in the Apple ecosystem to invoke an embeddable, 3-billion-parameter Foundation Model running entirely on the device itself. Everything stays on the device, including the model (which is downloaded and updated on demand). The infrastructure is wrapped inside a Framework (aka SDK), which is relatively straightforward for developers to understand.
Higher-level services, like Image Playgrounds, may use the Foundation Models, but if you ask it to do something that requires more computing (like a complex, multi-layered image with no connection to reality), it will fall back on server-side Private Cloud Compute.

Most LLMs return data in text format unless specifically instructed to return structured results, like common JSON. The problem is that even when specifically instructed, the results may not be correct, requiring extreme measures to clean up the mess.
Apple claims that its frameworks will not only retrieve structured data but also load it into user-defined data structures marked as @Generable, avoiding one of the taxing problems working with embedded LLMs.
Much like
For more detail, this WWDC-25 demonstration is worth a watch:
What’s also interesting is that the app can dynamically load and unload
# Side NoteIt’s interesting that Apple explicitly did not announce support for MCP in any of their tools.
This could be either because they wanted something that could run on a phone, tablet, or watch, because they just haven’t gotten around to it yet, or because they think their solution is superior.
Either way, the bifurcation creates a potential issue for future cross-platform tools like React Native, Capacitor, or Flutter.
The demo (above) shows how LLMs on the edge can be used in applications like games. This will undoubtedly be one of the most significant use cases for on-device, cost-effective AI.
There’s also support for a @Guide macro macro. This allows the developer to provide a free-form hint to the LLM so it conforms to an expected format.
@Generable
struct SportsTags {
@Guide(description: "The value of a sport, must be prefixed with a # symbol.", .count(3))
let sports: [String]
}
This takes it to another level if you have experience with Type Safety. It also opens up a pathway to the realm of completely decoupled function calls and parameter passing, which we’ll get to next.
Super-Late, Extra-Dynamic Binding
# The Phantom KnowsWhat if you combined shared libraries, dynamic linking, and web services and sprinkled in an ultra-dynamic AI search engine?
You would get what I will call
Phantom Binding .This is where the main application has no idea what the actual module invoked at runtime will be until an LLM (or similar mechanism) picks the
best one for the job and invokes it.And if such a function doesn’t exist, it could create one on-the-fly, test it, deploy it, then publish and cache it for next time.
If you are a developer, this either sounds like 🎉 or 😱. But it’s coming, and we all have a chance to make it safe and useful before it gets out of hand.
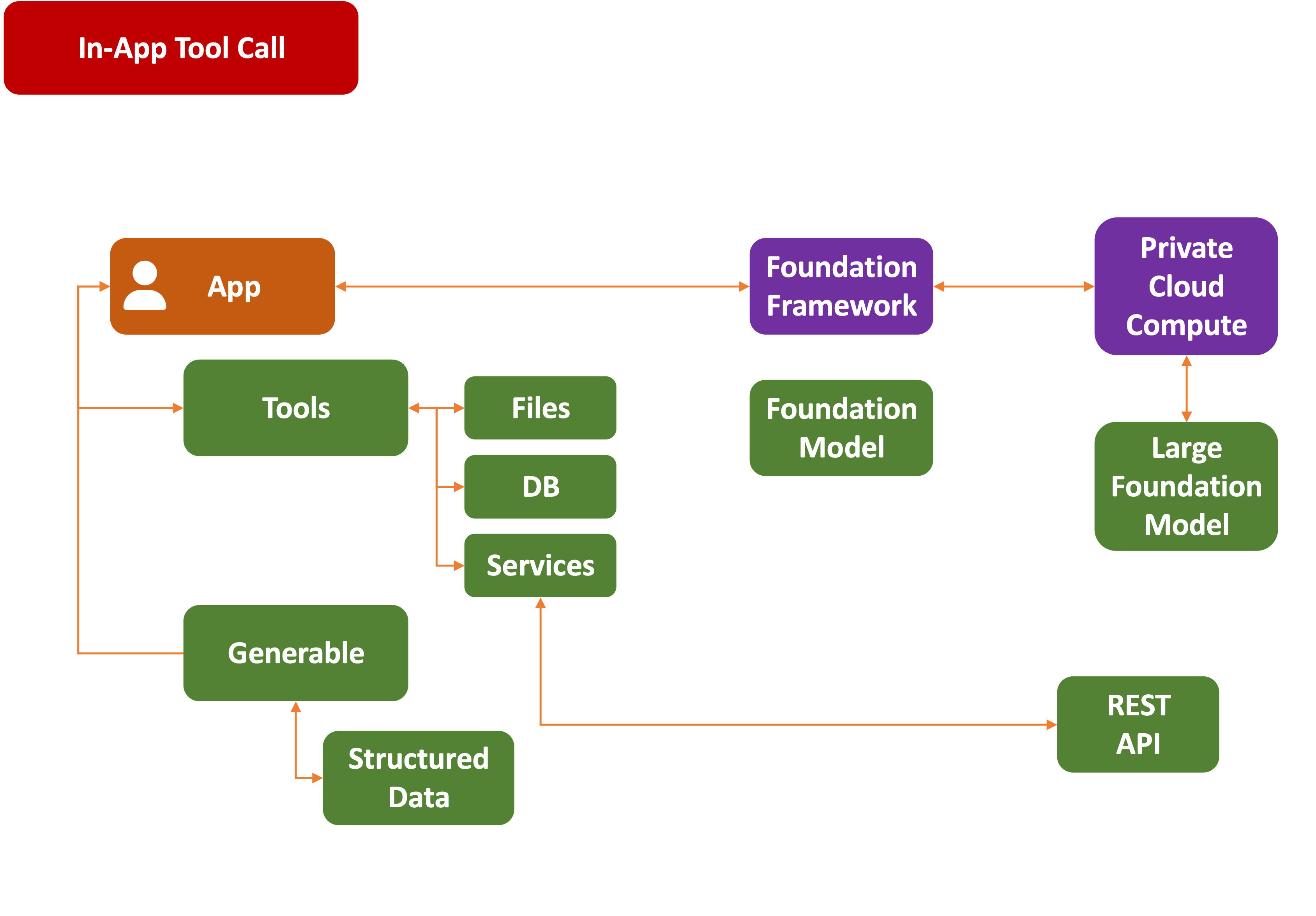
What’s different about adding tool support to LLMs is that:
-
They allow for a complete decoupling of the function from the calling application.
-
How to define what the tool does is in the description section in free-form text. It is then matched to the proper function at runtime.
-
They can be deployed in a range of formats: in-app, like
Apple Foundation Models , on your own computer usingLocal MCP servers , or viaRemote MCP Servers .
Here’s Apple’s in-app version:
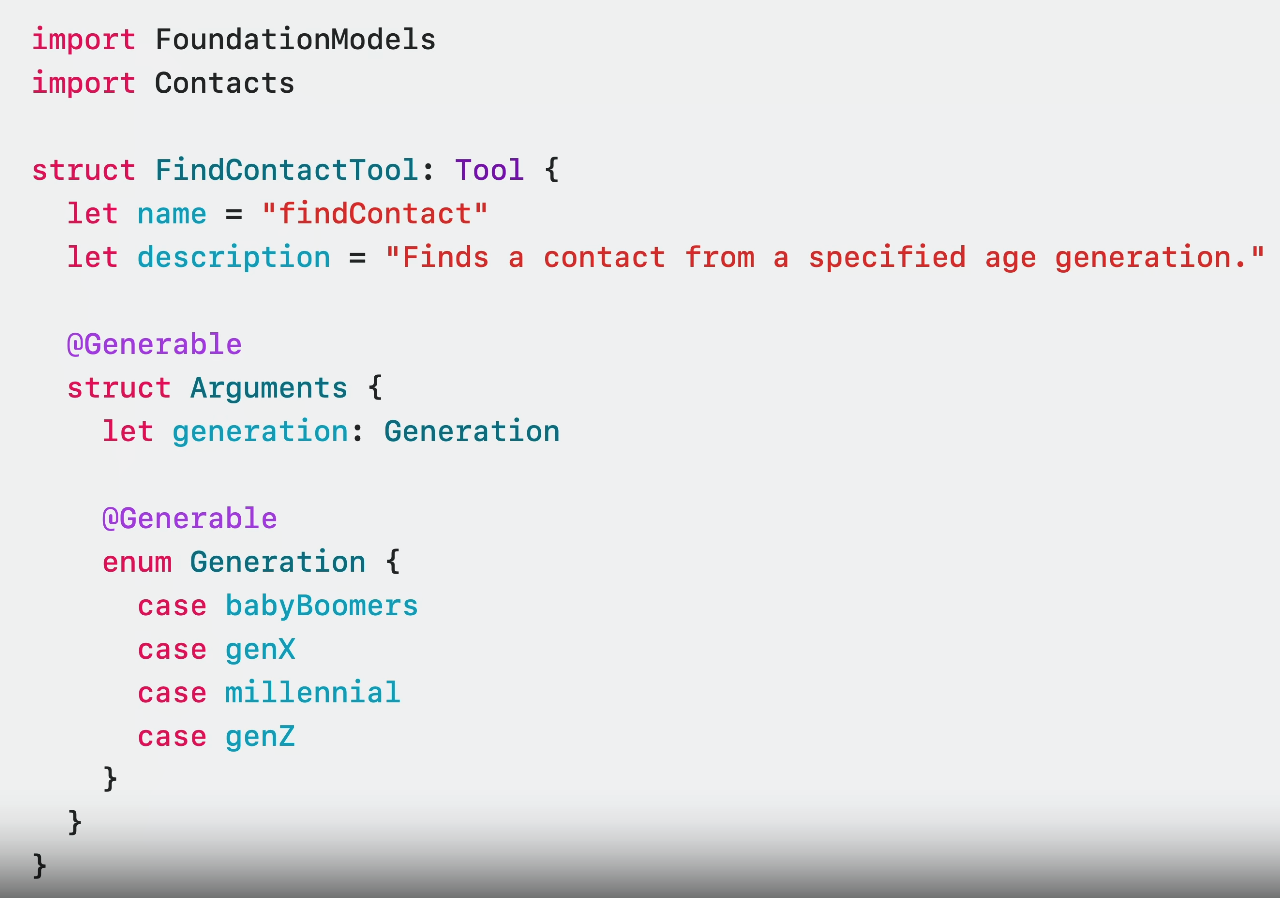
And here’s the MCP declaration:
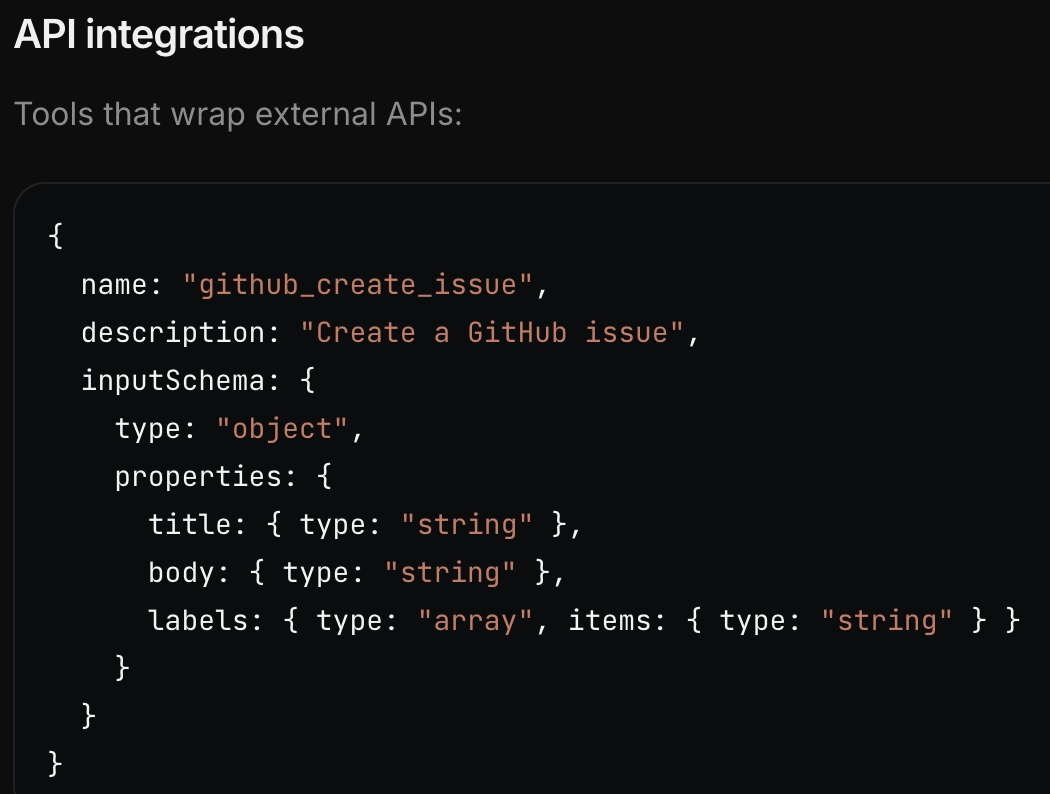
The
The Phantom Call

As we covered in a previous section, in most programming languages, a function call transfers control to any of the following:
- Built-in functions
- Included modules
- Shared libraries or dynamically loaded functions
- Remote-Procedure-Calls, or
- Web-services
Each has a different naming convention, parameter passing method, and invocation model, but they’re all doing the same thing:
But what if instead of explicitly declaring anything,
As we covered before, dynamic arbitration is a difficult (but solvable) problem.
So instead of a classic ‘C’ format call:
int sum(int x, int y)
{
int c;
c = x + y;
return c;
}
int main()
{
int a = 3, b = 2;
int c = sum(a, b);
…
}
What if you ended up with a
int main()
{
char* yum = ();
}
OK, fine. This is C. It needs a little more hand-holding:
int main()
{
int a = 3, b = 2;
int c = PhantomCall("multiply {a} and {b}", "use function with large integer support", a, b);
char* result = PhantomCall("name and score of MLB games where difference was larger than {c}", c)
...
}
This is the ultimate decoupling of an application, where each component is
This means that the system reaches out at runtime and locates services that can best handle the request. They could make this assessment in real time based on any number of parameters, like availability, cost, security level, contractual relationships, etc.
That’s precisely what High-Frequency Trading does. The cost of each transaction should be considered when deciding which function to call.
That’s how Real-Time Ad Bidding works.
It should even be possible to Federate the service providers into a
A system like this could implement local function calls, cloud-based functions, and even a future
Here’s how Phantom Function Calls might work:
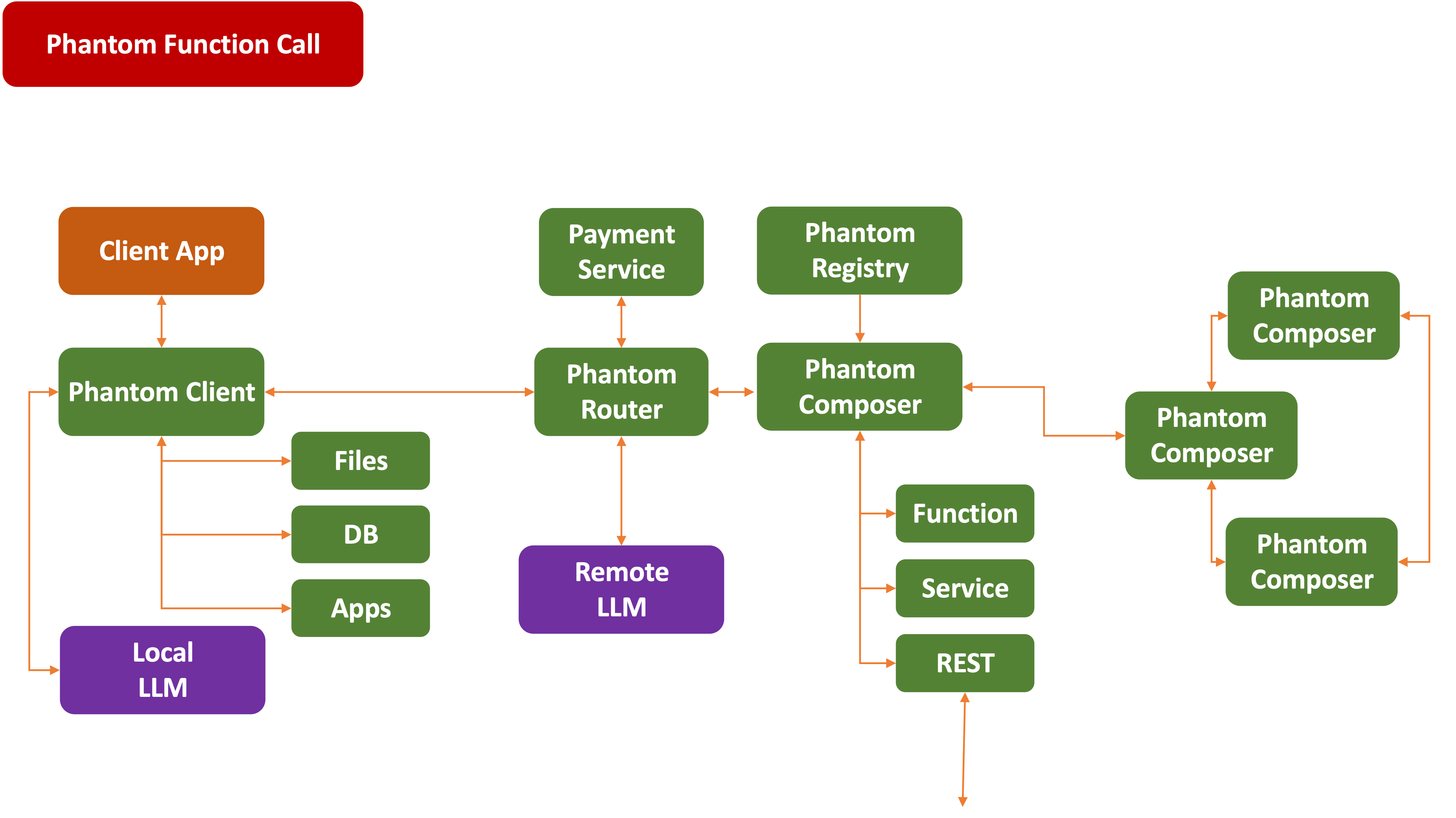
Tie this all into current
Making applications and services discoverable and
The Extreme

Let’s go one step further and wrap this all inside a programming language that ‘vibe-translates’ user intent into compiled binary code. It can take a user’s instructions, determine which extensions it will need, and then register for them during the compilation phase. At runtime, it would invoke the extension that best fits the requirements.
Another option would be to go fully dynamic and have the code interpreter determine which extensions it can access, then negotiate the calling interface and invoke it. Of course, some intelligent caching would be needed to make this all viable and not too slow.
Not enough?
How about a ‘vibe-code-creation’ mechanism that generates the code that would then do the above? This would allow for dynamic handling of circumstances beyond what the developer could have predicted.
In an ideal world:

Title illustration by Lee Falk: The Phantom (February 17, 1936), via Comic Book Historians.