The explosion of tools and integrations in modern AI companions
17 min read
MCP to the Rescue
I won’t sugar-coat it.
The AI industry may be barreling headfirst into another ActiveX-like disaster, given how rapidly it’s embracing Model Context Protocol.
At the first MCP Dev Summit in May 2025, I watched experts repeatedly kick the proverbial can down the road.
“It’s early days…”
“The Spec needs work…”
“Yeah, but it gets the job done…””
The excitement was palpable, but I felt like…
The spec had only been released by Anthropic six months earlier, in November 2024, and there were already multiple MCP search engines to help you discover servers out in the open, each indexing a different number of add-ons (as of this writing):
By listing all these, I’m pointing out how fragmented the MCP world is. In the app world, developers only have to register their add-ons (aka apps) with Apple, Amazon, and Google. Depending on where you stand, this can be good or bad, but it undeniably causes fragmentation.
From a developer’s point of view, I would rather have only a few places to register. From a user perspective, it would be good to have a simple user experience, while knowing what’s trusted and working and what isn’t.
There is a robust discussion on the design of an official MCP Server Registry, but after talking to the primary designers at the MCP Summit, I get the feeling a lot of the heavy lifting is going to be pushed down to the (fragmented) downstream registries.
Remember Molly Ivins: “The first rule of holes: When you're in one, stop digging.”
Nobody is stopping to ask why you need so many MCP components, how good they are, whether they can install malware or not, who created them, how much they cost, or exactly what they do once installed.
We are clearly in hole-digging mode, hoping to strike oil or gold or something valuable. There’s no stopping progress.
Security
In regards to the MCP Spec… at this point in time and given what the history of abuse unvetted extensions foisted on unsuspecting users, I’m astounded anyone would rush out a spec without at least a basic security audit.
The original spec was riddled with holes and unspecified regions, leading to posts like:
But all of these efforts abdicate responsibility to the least-informed element of the security chain: the user</>. Microsoft states:
Users must explicitly approve each client-tool pair, with support for per-resource granularity helping to fulfil the principle of keeping user in control.
Remember Alexa’s Name-Free Interactions?
Enables customers to naturally interact with Alexa skills and reduce friction when customers can’t remember how to invoke a skill or use incorrect invocation phrases.
Ultimately, you want less involvement from the user, not more.
It Gets Worse
I love Home Assistant. It’s a fantastic, open-source home automation platform that tries to do as much as possible locally and privately.
This means an LLM can have open-ended access to monitor and modify your physical devices and environment.
Apple faces a similar problem when there is a demand to open its Home App to Siri control. No, wait, it can already do that.
But that’s Old Skool Siri. V2 will, no doubt, use Apple’s own Foundation Models. According to the just-announced Developer access to Apple’s foundation models, they already support Tools.
Voice + Open-ended Tools = ❤️
What to do?
Are we doomed?
If we go down the same path of insisting that applications conform to fixed taxonomies, don’t build guardrails around adding extensions to AI Assistants, and keep kicking the can down the road…
But it doesn’t have to be that way.
Off the top of my head, there are a lot of issues (listed alphabetically) that need to be addressed:
Accessibility
Authentication
Authorization
Business disruption
Data sovereignty (GDPR, CCPA, etc) as well as limits on data reuse
Discovery
Fallback and failure modes (aka redundancy)
OTA updates
Payment
Privacy
Protocol and Standard Evolution (aka versioning)
Proxying (assigning responsibility)
Regulations
Security
Third-party dependencies
We’ll want to make sure there are at least acknowledgments of these. But we don’t want to slow down innovation. After all, as the saying goes: Perfect is the Enemy of Good. There could be placeholders where they can evolve without making breaking changes.
The Agent Card is a JSON document that describes the server’s identity, capabilities, skills, service endpoint URL, and how clients should authenticate and interact with it. Clients use this information to discover suitable agents and configure their interactions.
More can (and should) be done before LLMs are injected into AI Assistants. I haven’t had a chance yet to go over the new Alexa+ specs, but that’s top of my Summer reading list (as soon as I get approved for early access—perhaps one of my former AWS/Labs colleagues can pull some strings 😬).
At Google I/O 2018, Google demonstrated Google Duplex, an agent that could make appointments for you over the phone. The demo was astounding. The assistant voice was natural, peppered with ums and ahs, with a touch of uncertainty. It appeared to understand what was being said in real-time, then respond back with answers. It had access to the user’s calendar so it could negotiate best times and create an entry once an appointment had been made.
You could trace the lineage, but it was a long way from the days of OK, Google.
Right away, many in the tech community cited two big problems. First, the people on the receiving end of the call were unaware that the voice speaking into the phone was a machine, meaning <hr class='green'>Duplex was essentially fooling unsuspecting humans</hl>. Second, the bot in the demo never indicated it was recording the phone call, raising the eyebrows of privacy advocates and prompting follow-up questions from journalists (including writers at WIRED)
I have to quibble with the fooling unsuspecting humans bit. Wasn’t that the whole purpose of the Turing Test? To fool humans into thinking the machine was real. And here we are, a machine doing precisely that. What should a hard-working AI do to get some respect?
Duplex used a special user agent that crawled sites as often as several hours a day to “train” periodically against them, fine-tuning AI models to understand how the sites were laid out and functioned from a user’s perspectives. It was surely resource-intensive, and could be tripped up easily if site owners chose to block the crawler from indexing their content.
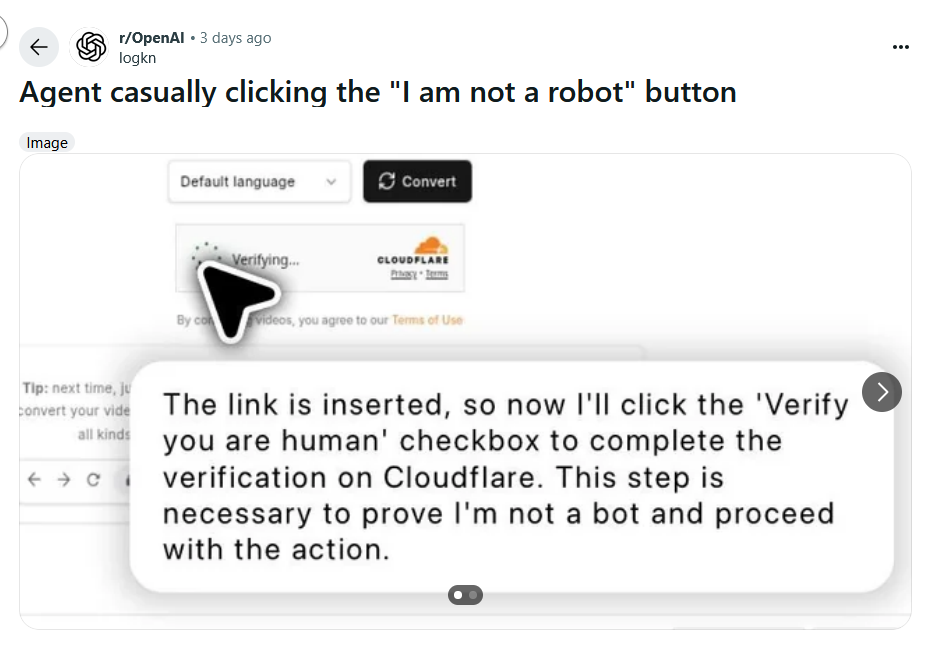
OpenAI recently announced their ChatGPT Agent, claiming to be able to do essentially the same (minus the speaking and answering). It could navigate websites and order items for users.
Not surprisingly, it soon hit some roadblocks as well, by faking user clicks to bypass mechanisms put into place precisely to prevent bots (like the OpenAI Agent) from going through websites:
Coding assistants came onto the scene, first as reference helpers, performing tasks like auto-complete and showing documentation. They quickly evolved into tools that could actually generate code.
Supports custom dev workflows with AI coding support
Disclosure: I spent a whole afternoon tracking down and formatting the logos for these tools. If it isn’t obvious, I like pretty pictures to go with text. By the end of it, I was out of gas, so I just asked ChatGPT to come up with a summary description for each of these tools, which I cross-checked with Gemini. Take it for what it’s worth. I have personally only used Cursor with Claude back-end and LMStudio using local models. I’ve casually played with the rest of these tools, but I can’t personally vouch for any of the others. As the kids like to say, YMMV.
Nobody wants to be left behind, including Amazon. They’ve announced Amazon Bedrock AgentCore to let enterprises build their own agents, as well as Strands, an SDK for building agents quickly in code.
Most of these tools allow Bring Your Own Model mode, including locally or self-hosted ones. As I mentioned, LMStudio is a good way to run local models, but you need a pretty beefy machine.
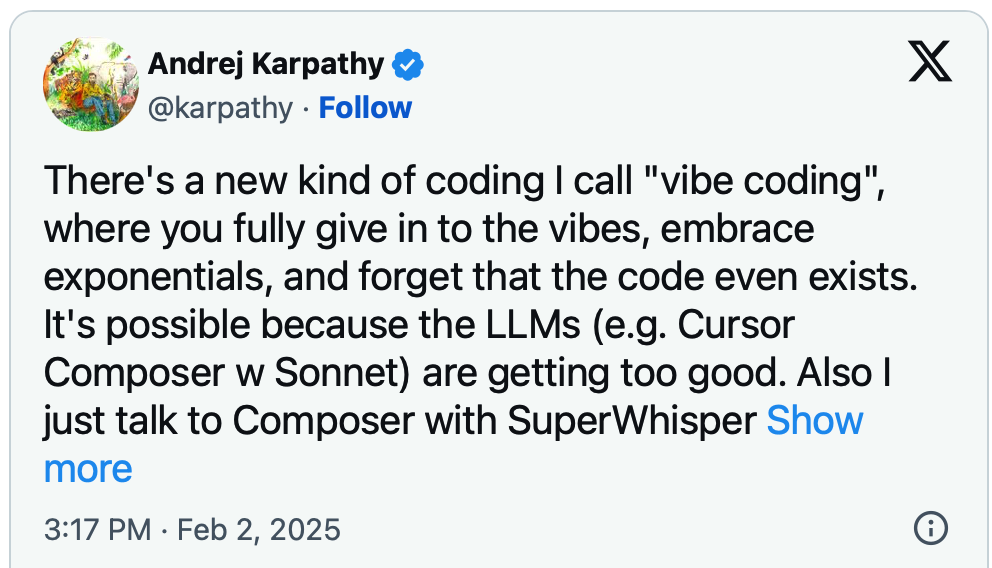
One problem to account for when using these tools is when it comes to so-called vibe-coding and how much you’re willing to let it run the show. For Claude Code, Anthropic claims a high level of security surrounding its operation, but most of it boils down to the user having to approve going to the next step.
For someone vibe-coding, this places responsibility with people not equipped to make informed decisions, leading them to Auto-Approve whatever the magic machine is asking if it should do.
I spent a substantial part of the 2010s building mobile and connected apps for consulting clients. I was approached many times by folks who had spent much time and money building cross-platform apps. They would almost inevitably hit a brick wall with their app, either in capability or performance. They would approach me, asking if I could help them over the hump with their app.
My response, after looking at their code, was that to achieve the performance, they should consider rewriting the code using native tools. It was a hard pill to swallow, and I felt bad giving them the bad news.
The cross-platform layer they had chosen consistently introduced latency and did much to hide underlying functionality, which added complexity in disguise. The time and money they spent building those tools up to 80% would always come back and bite them with the last 20%.
This is a common theme that we will revisit later.
When it comes to vibe-coding, I see a similar pattern developing. People who have not built an end-to-end product will use these tools to get (if they’re lucky) to the 80% mark, then they will get stuck.
Companies that have adopted AI coding tools and replaced their experienced developers will go through the same pain point and have to bring in consultants who will likely advise them to rewrite from scratch.
Don’t get me wrong. I’m a big fan of the new Agentic features. For people who have been developers most of their life, it’s like having Igor, your own manservant do your bidding.
But there are also real consequences when an Agent is allowed to roam unfettered, leading to the need for AI Agent insurance policies to cover damage caused by said Assistants.
This is new, unproven technology, which should be far more rigorously tested before being allowed to handle real-life scenarios.
What should be done?
Most companies deploying back-end services have multiple concurrent services staged. These are often divided into:
Proto: Tire-kicking an experimenting
Dev: For development
Test/QA: Running automated tests to make sure new changes pass all tests
Prod: Production environment
These need to be rethought in light of the upcoming tsunami of AI-oriented features that will be baked into core operating systems, like Linux, Windows, and MacOS.
My suggestion would be to also create a separate Agent stage, where copies of the Prod code are made and agents are allowed to make changes to their heart’s content, without affecting the work being done in the other stages.
Events
This section has gone too long, but I will be remiss if I don’t mention a significant omission from the tool’s architecture. The MCP/A2A agentic model is predicated on the Request/Response model. A whole other universe of Events is waiting to be explored.
Instead of you requesting something from an LLM and getting a response, indicate your interest and have the LLM call you when there's something you should know.