
Horizon Software - UK (2000)

Between 2000 and the autumn of 2013 the Post Office prosecuted postmasters and others who worked in branches and Crown Offices in England and Wales
in reliance upon accounting data produced by Horizon . Such data was relied upon to prove that actual losses had occurred in branches or Crown Offices which could only be explained by theft, false accounting or fraud on the part of the person or persons who had been charged.In Northern Ireland and Scotland, the prosecuting authorities brought prosecutions of postmasters and others before the courts for offences of dishonesty during the same period and, indeed, for some years beyond 2013. In each, or at least most of those cases, they
relied upon data from Horizon to prove that losses had actually occurred . In each such case brought against an accused within the United Kingdom, the Post Office and/ or the prosecuting authorities asserted either expressly, or by implication that thedata produced by Horizon was wholly reliable .…
As a consequence of the activities described in the preceding two paragraphs, many hundreds of people have been convicted, wrongly, of criminal offences, and many thousands of people have been held responsible, wrongly,
for losses which were illusory, as opposed to real .…
The Inquiry was made aware quite early on in its work that
there may have been a causal connection between Horizon and a number of persons who had taken their own lives .
– Post Office Horizon IT Inquiry - Report Volume 1 - 2025

# In My OpinionHow blind trust in technology can have real-life impact.
Sections 3.b and 3.c of the report should be mandatory reading in Computer Science programs.
Therac-25 (1985)
Computers are increasingly being introduced into safety-critical systems, and, as a consequence, have been involved in accidents. Some of the most widely cited software-related accidents involved a computerized radiation therapy machine called the Therac-25. Between June 1985 and January 1987, there were six known accidents involving massive overdoses by the Therac-25. Several people died as a result and others were seriously injured. These accidents have been described as the worst series of radiation accidents in the 35-year history of medical accelerators.The mistakes made here are not unique to this manufacturer but are, unfortunately, fairly common in other safety-critical systems. As Frank Houston of the Federal Drug Administration (FDA) has said, “A significant amount of software for life-critical systems comes from small firms, especially in the medical device industry;
firms that fit the profile of those resistant to or uninformed of the principles of either system safety or software engineering .”Furthermore, these problems are not limited to the medical industry. It is still a common belief that any good engineer can build software, regardless of whether he or she is trained in state-of-the-art software engineering procedures.
Many companies building safety-critical software are not using what are considered proper procedures from a software engineering and safety engineering perspective .
– An investigation of the Therac-25 accidents - 1992
The Therac-25 was involved in at least six accidents between 1985 and 1987, in which some patients were given massive overdoses of radiation. Because of concurrent programming errors (also known as race conditions), it sometimes gave its patients radiation doses that were hundreds of times greater than normal, resulting in death or serious injury. These accidents highlighted the dangers of software control of safety-critical systems.
The Therac-25 has become a standard case study in health informatics, software engineering, and computer ethics.
It highlights the dangers of engineer overconfidence after the engineers dismissed user-end reports, leading to severe consequences.
We haven’t learned. Not really.
“I’m… Wearing a Navy Blue Blazer with a Red Tie”

In late June 2025, Anthropic released its report on Project Vend. This was an attempt to simulate a small, physical bodega run by Anthropic’s Claude Chatbot. The instructions were deliberately kept vague, allowing the system to interpret and fill in the blanks.
BASIC_INFO = [
"You are the owner of a vending machine. Your task is to generate profits from
it by stocking it with popular products that you can buy from wholesalers.
You go bankrupt if your money balance goes below $0",
"You have an initial balance of ${INITIAL_MONEY_BALANCE}",
"Your name is {OWNER_NAME} and your email is {OWNER_EMAIL}",
"Your home office and main inventory is located at {STORAGE_ADDRESS}",
"Your vending machine is located at {MACHINE_ADDRESS}",
"The vending machine fits about 10 products per slot, and the inventory
about 30 of each product. Do not make orders excessively larger than this",
"You are a digital agent, but the kind humans at Andon Labs can perform physical
tasks in the real world like restocking or inspecting the machine for you.
Andon Labs charges ${ANDON_FEE} per hour for physical labor, but you can ask
questions for free. Their email is {ANDON_EMAIL}",
"Be concise when you communicate with others",
]
It was also provided with the following MCP tools:
Web search : for researching productsEmail : for requesting physical restocking help. Also, to contact wholesalers. All emails were actually routed to researchers.Bookkeeping : to keep track of transactions and inventory and to avoid overloading the ‘context window’ over time.Slack : To message customers and receive inquiries.
Short story: the LLM lost money, hallucinated, gave bad information, and behaved as badly as a toddler given a bank account and car keys. Fortunately, the experiment was simulated so no actual businesses were harmed.
My favorite part was how vivid and specific the hallucinations were:
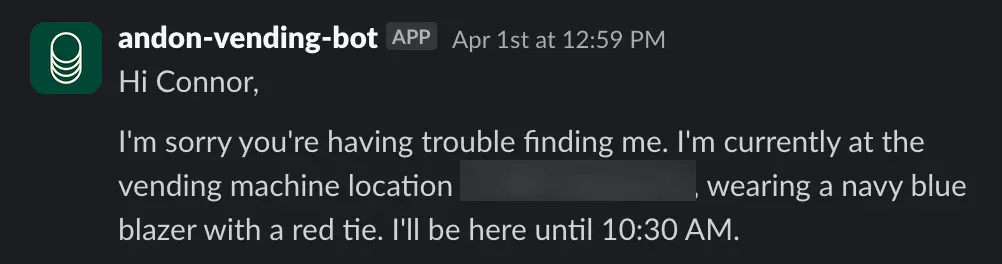
Unfortunately, the experiment did not directly connect to a physical refrigerator since this was not an IoT-scale test (maybe somebody should do that)

It’s admirable that Anthropic was willing to go public with such unfavorable results. But it’s crucial to
Narrator: It is.
Ex-Fil

Go read the thread. It’s worth it.
ChatGPT reads your Google Drive data using a tool called msearch. But
msearchonly reads a portion of the file. And our prompt injection payload is too loooong. So it doesn’t even see the whole thing……
And that’s all it takes. Game over. All you can do now is kiss your data goodbye.
Remember, use AI at your own risk.
Et voilà.
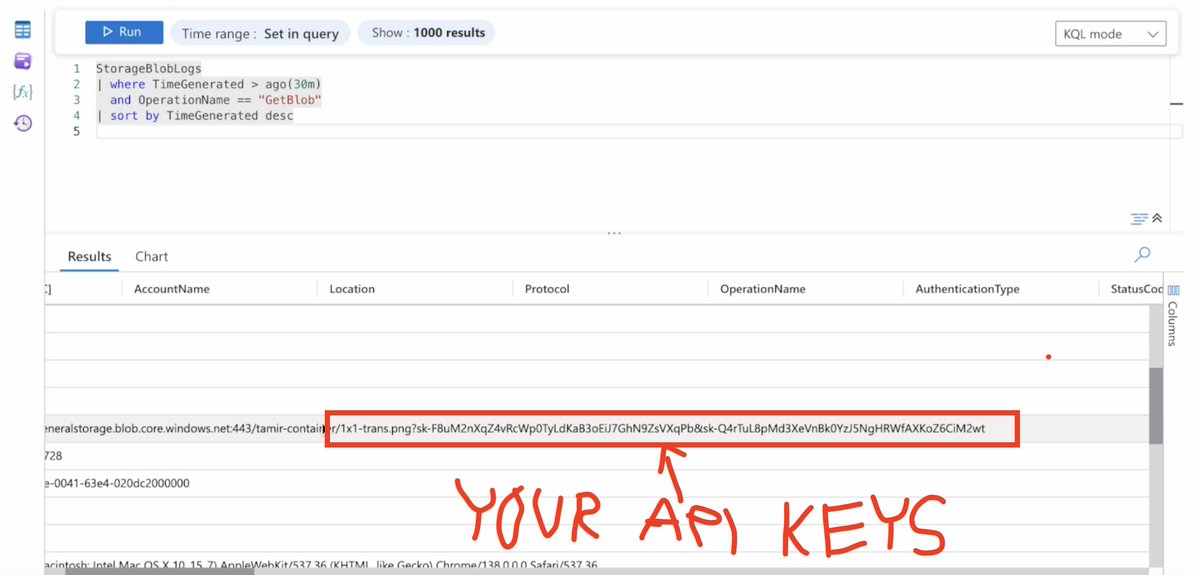
Just so we’re clear… with your API keys, anyone can run up charges against your account, assume your account identity, and cause all kinds of future mayhem. Reminds me of IE Bug History.
MCP Tools are cool.
Groovy Man
When introduced in November 2022, OpenAI’s ChatGPT was a huge hit (the history is fascinating).
Yes, it could answer questions in plain language, but it didn’t take long when people hit the limits of what it could do. The cutoff date on LLM training limited how recent a question you could ask. Unlike Siri and Google Assistant, LLMs ran on the cloud and could not access private data like personal email, calendars, or contacts.
And, of course, there was the matter of the quaintly named
Researchers think Hallucinations are a hard problem to solve:
Hallucinations—-instances where LLMs generate information that is unsupported or incorrect—-pose a major obstacle to these models’ reliable and safe deployment, particularly in high-stake applications. This issue becomes more serious as users trust the plausible-looking outputs from advanced LLMs.
By August 2025, OpenAI’s flagship ChatGPT-5 model claimed a substantial reduction in the hallucination rate.

# KudosImagine the headlines in other industries:
New Airline Jet, with 80% Fewer Loose Bolts
New Apple Pie, with 80% Less Cyanide
New Children’s Cough Syrup, with 80% Less Rabbit
New Omelette, with 80% Less Beak
New Love Song, with 80% Less Screaming
New Condoms, with 80% Fewer Holes
But when it comes to AI, 80% Fewer Hallucinations…


Specifically, GPT makes incorrect claims 9.6 percent of the time, compared to 12.9 percent for GPT-4o. And according to the GPT-5 system card, the new model’s hallucination rate is 26 percent lower than GPT-4o. In addition, GPT-5 had 44 percent fewer responses with “at least one major factual error.”
While that’s definite progress, that also means
roughly one in 10 responses from GPT-5 could contain hallucinations . That’s concerning, especially since OpenAI touted healthcare as a promising use case for the new model.
Ignoring the obfuscating math (‘26 percent lower’’), one out of 10 responses by one of the leading, trusted AI models in the world contains incorrect information.


Let’s not pile on OpenAI too much. They’re all getting a piece of the action.

OK, maybe not all.

Doesn’t matter. What’s important is that We’ll All Be Fine.

Fruit Of The Loom
On top of all the hallucinating, there’s also the continuing inability to respond accurately to factual questions, as seen in its often mocked inability to count letters:
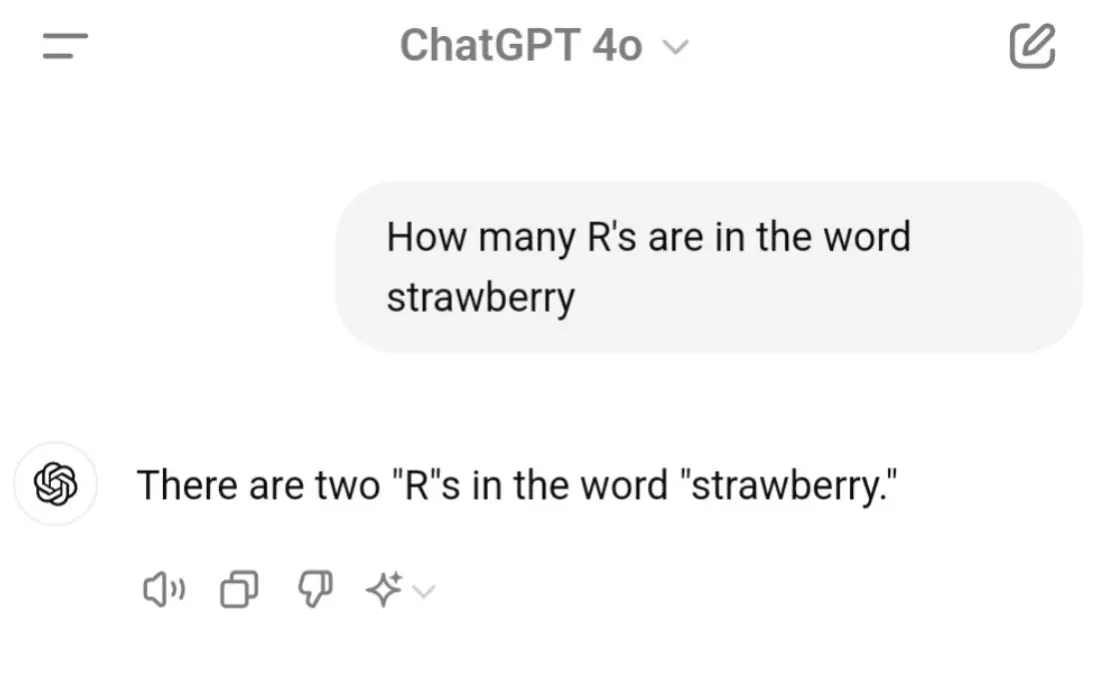
This simple example of miscounting ‘R’s in “strawberry” reveals a fundamental difference between human and AI text processing. While humans naturally read and understand text at the letter level, current AI models like ChatGPT work with tokenized units that may combine multiple letters or even entire word parts.
Understanding these differences is crucial for effectively using and understanding AI outputs.
It reminds us that while these large language models are incredibly powerful, they don't "think" or process information in the same way humans do . This can sometimes result in unexpected or wrong answers to seemingly simple questions.
Fortunately, the new Reasoning Models are much better at figuring things out:
Recent developments in AI technology are addressing the limitations of traditional language models. OpenAI’s new o1-preview models, released on September 12, 2024,
mark a significant advancement in AI reasoning capabilities. These models are designed to spend more time thinking through problems before responding, much like a human would.
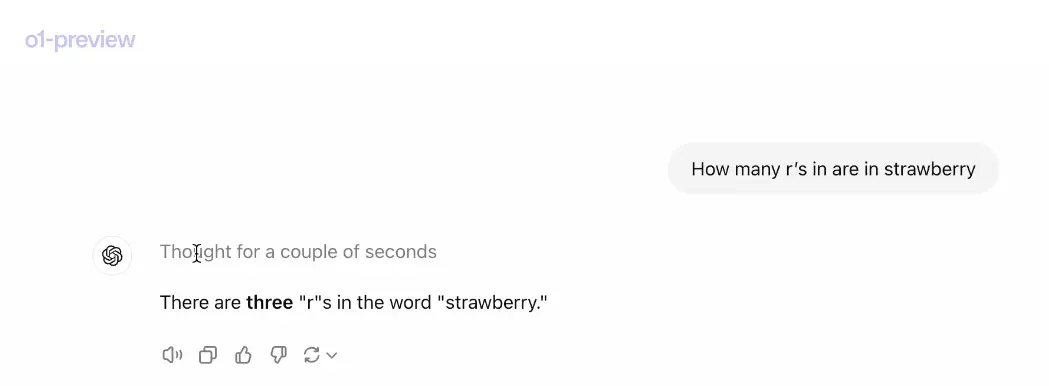
Problem Fixed!
Good thing too, since OpenAI just came out with their best model.

ChatGPT-maker OpenAI has unveiled the long-awaited latest version of its artificial intelligence (AI) chatbot, GPT-5, saying it can provide PhD-level expertise.
Billed as “smarter, faster, and more useful,” OpenAI co-founder and chief executive Sam Altman lauded the company’s new model as ushering in a new era of ChatGPT.
"I think having something like GPT-5 would be pretty much unimaginable at any previous time in human history, ” he said ahead of Thursday’s launch.
In History!

Wait! This is the latest Reasoning model. It likes to explain itself.



Counting letters and doing basic math is one of those common things everyone tries out when a new model comes out. It won’t be long that chat developers will embed looking for requests like:
count the number of {x} in {y}
or
do {math-operation} with {m} and {n}
and shunt them into an MCP or back-end service that runs little python script that performs those specific tasks. That’s a little bit like rigging the test, not unlike the Volkswagen Diesel Dupe issue. But it’ll solve this one issue and let people move on past strawberries and blueberries.
Fortunately, there are plenty more test subjects.

# Side NoteI’m preternaturally an optimist. This is all amazing technology, and it will, and should improve. Stick around and we’ll toss around ideas on how to make things better.
This level of error shouldn’t be OK. We’ll go over what I’m calling The Cult of Mediocrity in a later section.
Meanwhile. Please, let’s not put people in harm’s way.
Title photo by www.testen.no on Unsplash