

“Prince Ivan has come and has carried off Marya Morevna.”
Koshchei galloped off, caught Prince Ivan, chopped him into little pieces, put them into a harrel, smeared it with pitch and bound it with iron hoops, and flung it into the blue sea. But Marya Morevna he carried off home.
At that very time the silver articles turned black which Prince Ivan had left with his brothers-in-law.
“Ah!” said they, “the evil is accomplished sure enough!”
Then the Eagle hurried to the blue sea, caught hold of the barrel, and dragged it ashore ; the Falcon flew away for the Water of Life, and the Eaven for the Water of Death.
Afterwards they all three met, broke open the barrel, took out the remains of Prince Ivan, washed them, and put them together in fitting order. The Eaven sprinkled them with the Water of Death — the pieces joined together, the body became whole. The Falcon sprinkled it with the Water of Life — Prince Ivan shuddered, stood up, and said :
“Ah! What a time I’ve been sleeping!” “You’d have gone on sleeping a good deal longer if it hadn’t been for us,” replied his brothers-in-law. “Now come and pay us a visit.””
“Not so, brothers; I shall go and look for Marya Morevna.”
The Death of Koschei the Deathless, in The Red Fairy Book (1890)
If you read the last piece, you may think loss of Privacy is a foregone conclusion. That the cows may have already left the proverbial barn.

You may be right. It’s frighteningly easy to get detailed information on anyone.

Or inadvertently be part of a leak that contained some of your information.
Even governments, under the guise of protecting children, are getting into age-gating you.


However, I’m an idealist, and I think it’s still worth taking a stab at starting fresh and coming up with something that allows us to retain some semblance of control over what we share and for what purpose.

Let’s go.
The Basics
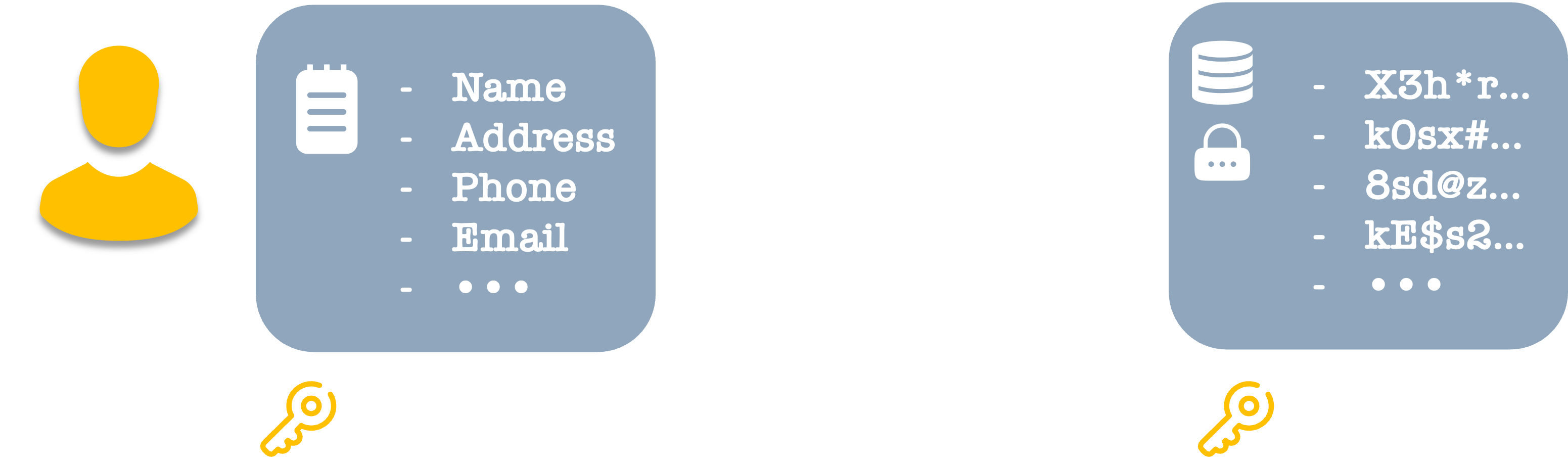
Let’s start simple. Each of us has specific attributes associated with us. Think of them as a list of keys (aka names) and values.

In some cases, the data may have more of a hierarchical scheme, allowing certain data to be collated together.

In other cases, we may want to maintain relations between different types of data. These are often called Graph Data, consisting of nodes (aka entities) and edges (relationships). The relationships may also be bi-directional.
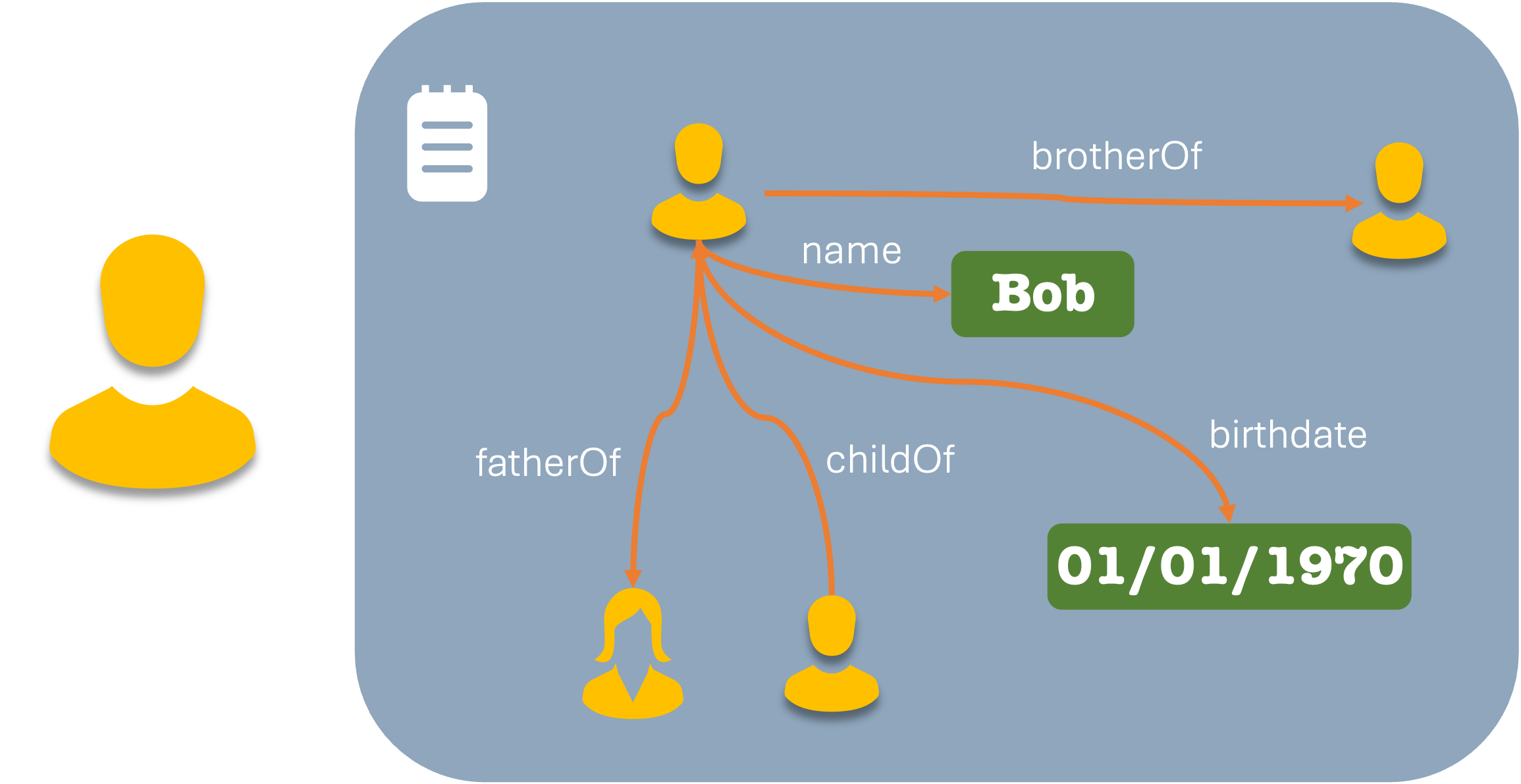
But for the sake of simplicity, let’s stick with that first flat data structure.
Categories
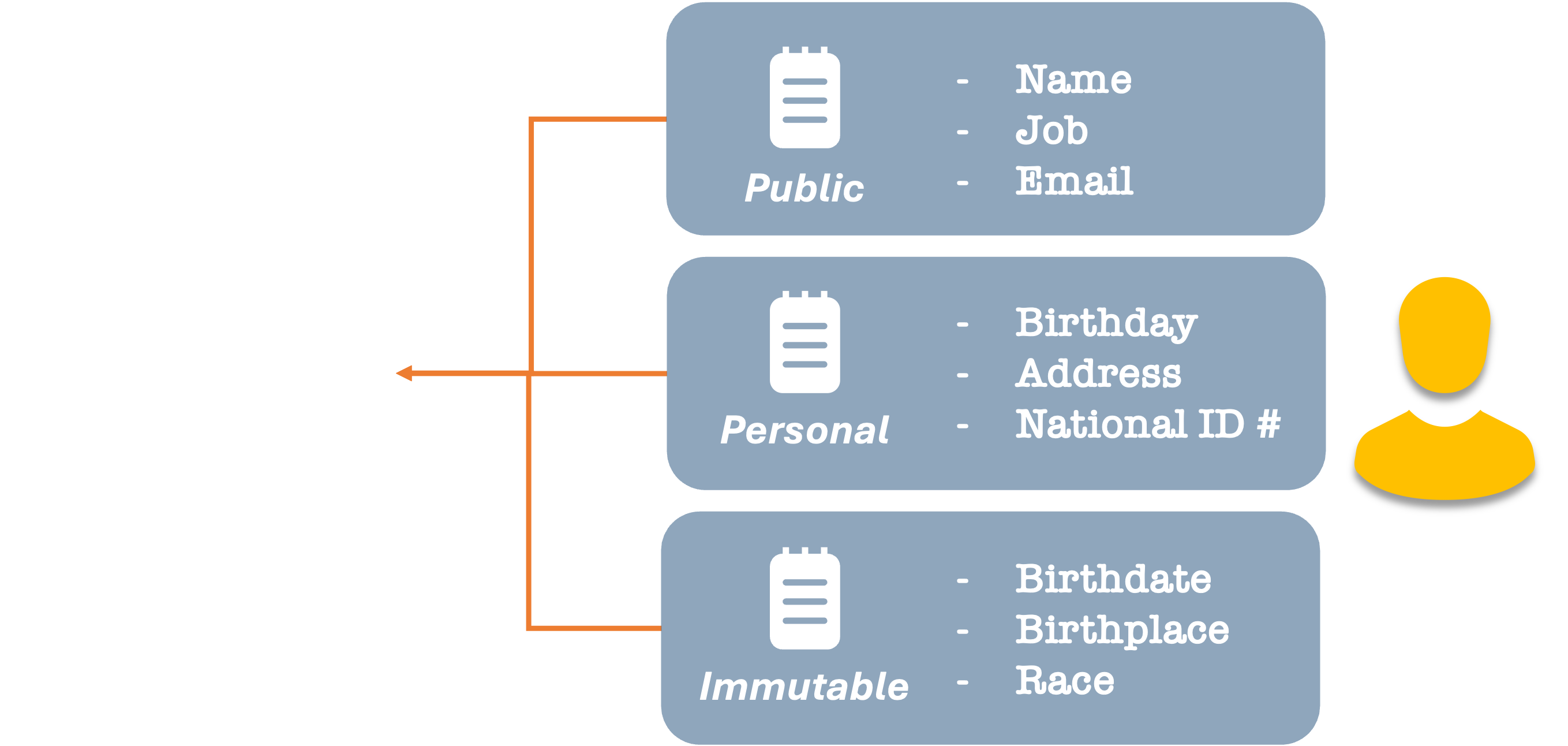
Some of our data may be considered private, and some public. Others may be changed (mutable) or remain frozen (immutable).
For example, our name may be public, but we may want to keep our bank account number or sexual identity private. Data like where we were born, our birthday, or our race can not be changed (at least, until a real, working time machine is invented). These are considered fixed or immutable.
Values like our home address, school, place of work, email address, or phone number can change over time, either by us or by entities assigning them to us.
Certain others may seem fixed, like our name. But we can (and some do) legally change it.

Captain Fantastic claims world’s longest name
Wednesday 05 November 2008
A Glastonbury teenager is claiming to have the longest name in the world - Captain Fantastic Faster Than Superman Spiderman Batman Wolverine Hulk And The Flash Combined.
Captain Fantastic - formerly George Garratt - changed his name by deed poll “for a bit of a laugh” through a service he found online.
We can assign these values to arbitrary categories, based on who can see them and whether they are innate to us, such as our height, or assigned to us like a job title, membership number, or driver’s license number.
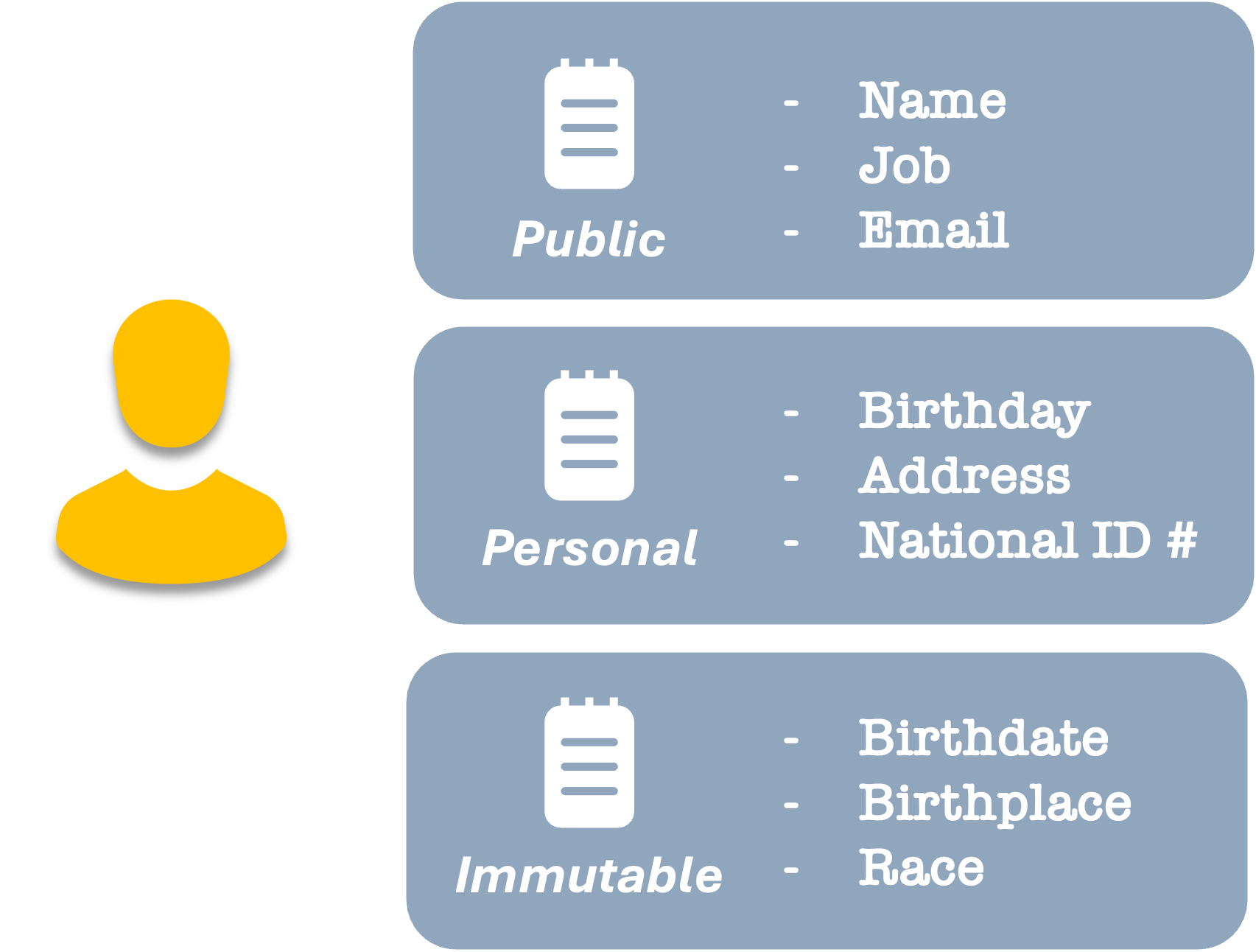
In fact, there can be many different categories or groupings. But there is a long list of items that are inherently our data.
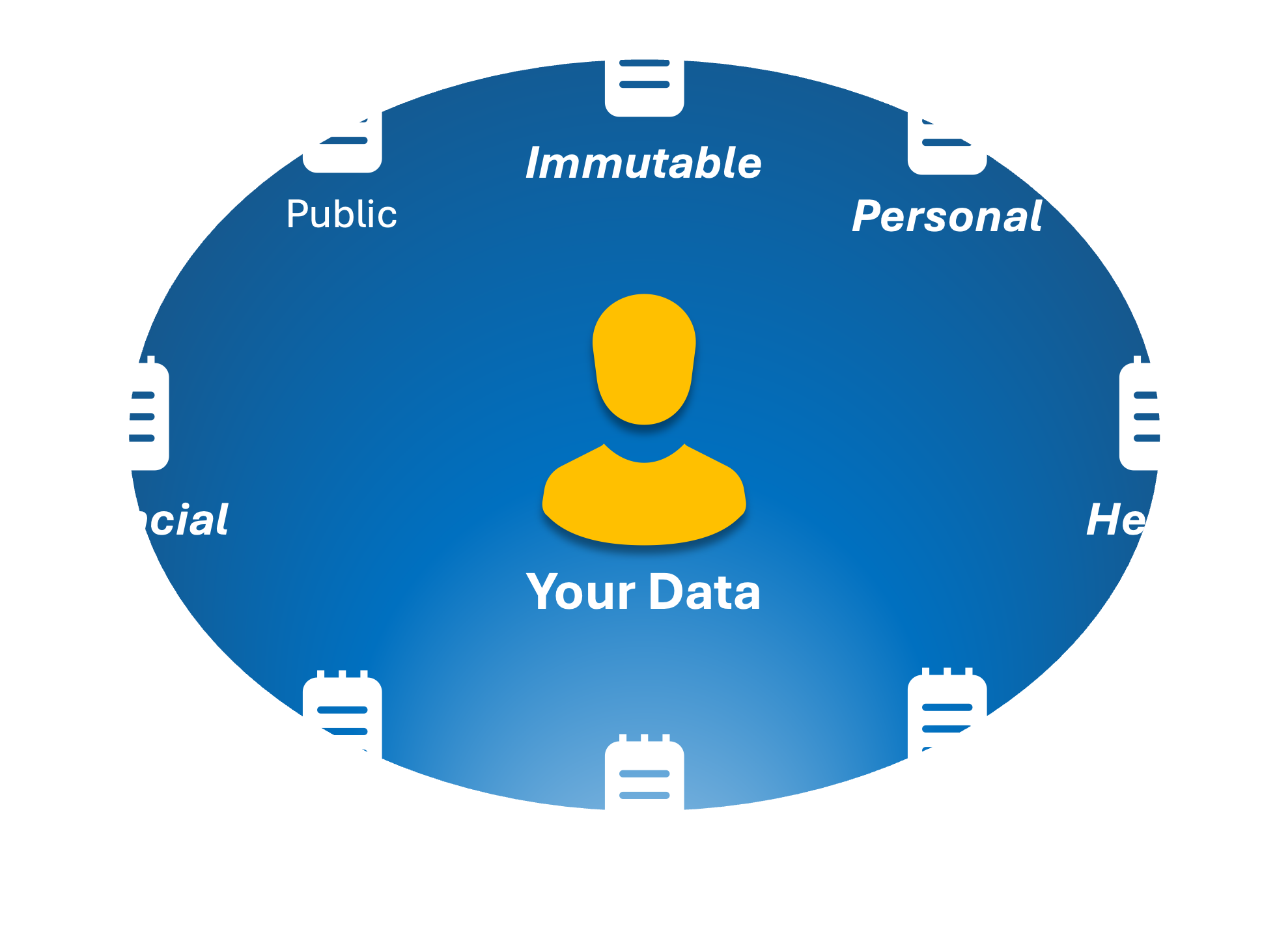
When we share our data with someone else, we take a sub-sample of data elements and present them as one or more views onto our data. Let’s think of them as a lens or facet. There can be many of these groupings. For example, we have specific combinations of values that we need to share with work (for legal or company policy reasons).
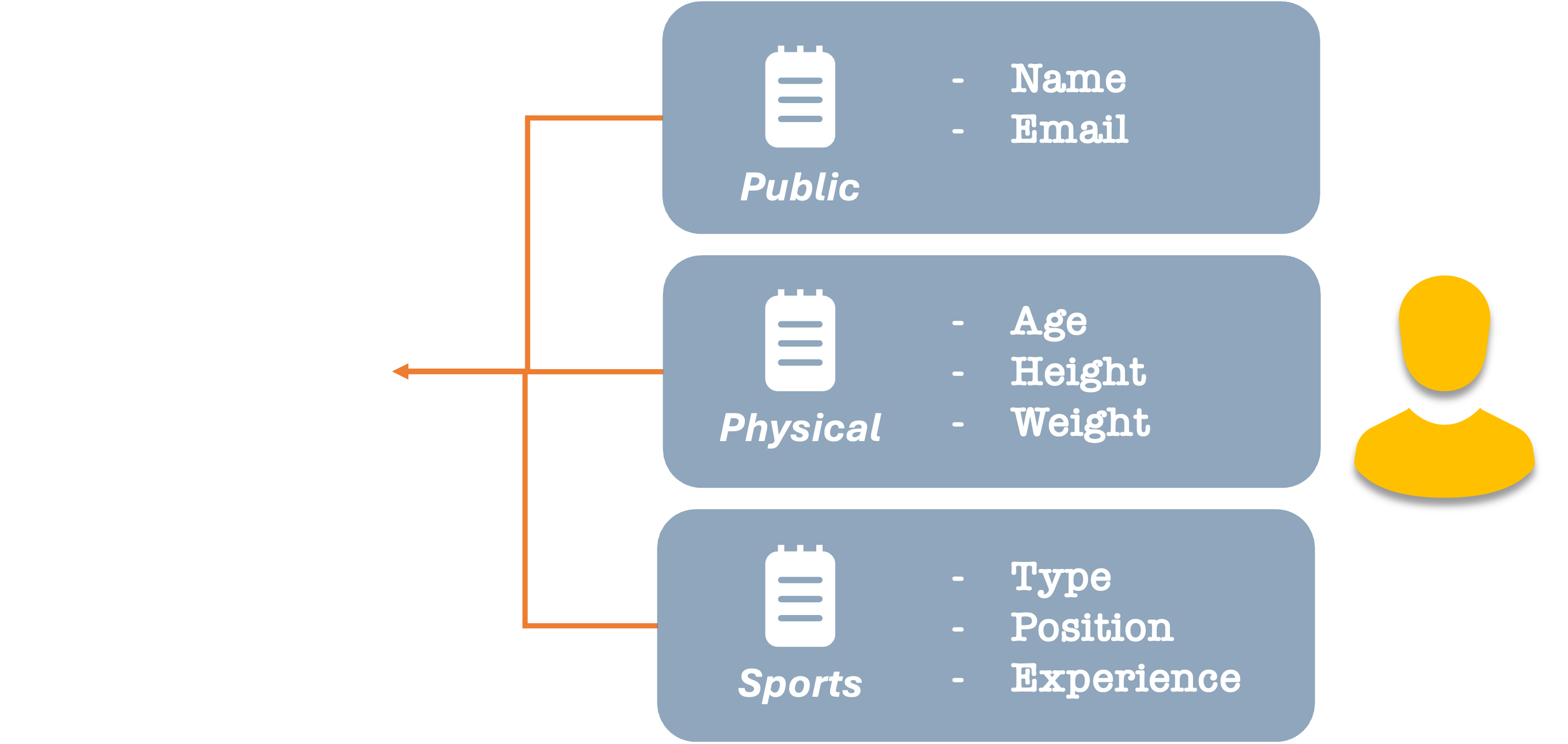
But if we’re joining a sports club, there may be values more relevant to that setting.
Still with me? Excellent! Let’s press on.
As mentioned earlier, some of the data may be read-only or immutable, while others may be modified. What’s more, we may only want to allow certain entities the ability to modify them. For example, our medical records can only be updated by a qualified medical provider.
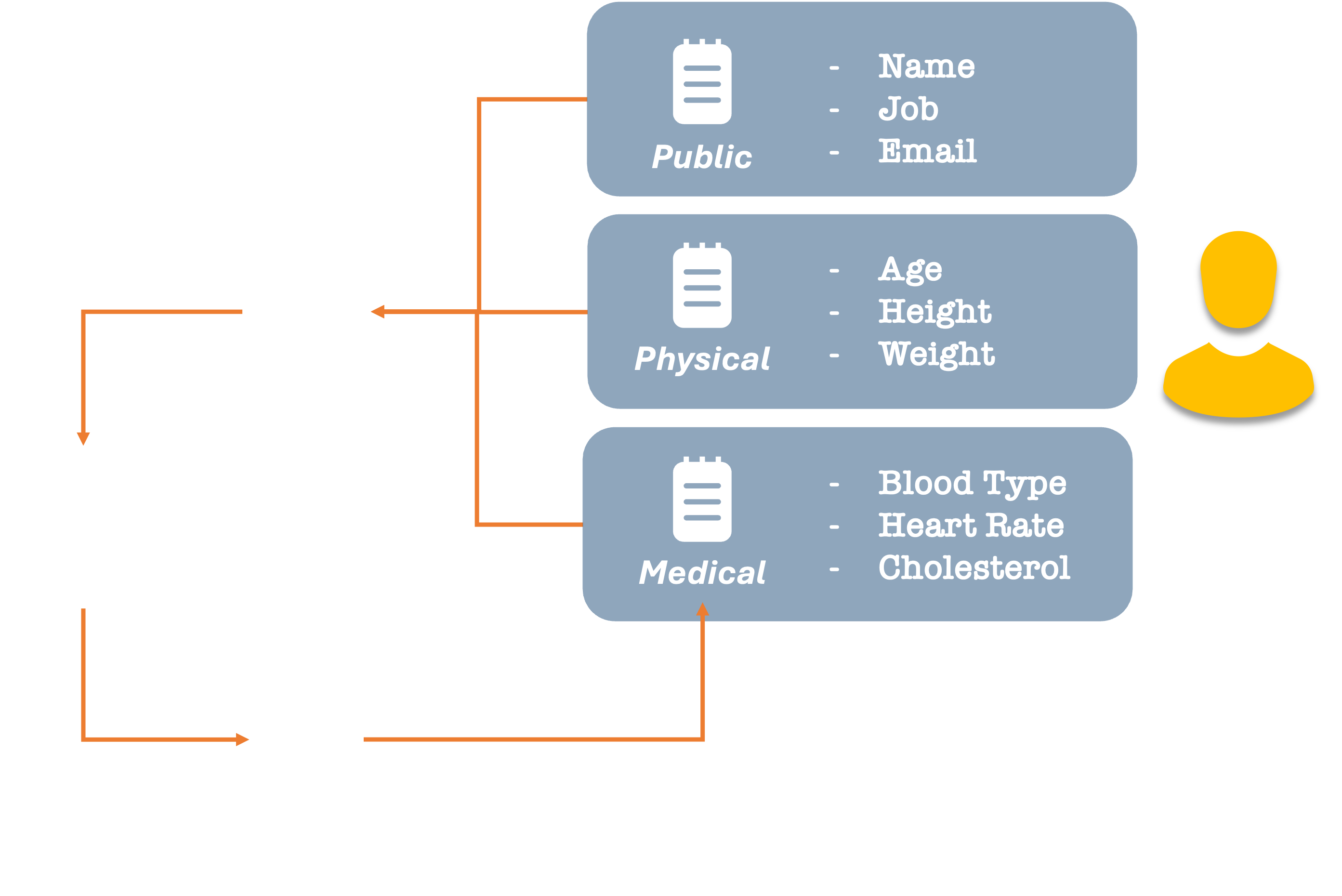
Now wait a minute! You might say. My medical records are kept with my doctor, hospital, insurance company, or government health service. I don’t really own my medical data!
And you would be right. Except most of these healthcare entities appear to be having trouble keeping that data private:
The HIPAA Journal has compiled healthcare data breach statistics from October 2009, when the Department of Health and Human Services (HHS) Office for Civil Rights (OCR) started publishing summaries of healthcare data breaches on its website. … Our healthcare data breach statistics clearly show
there has been an upward trend in data breaches over the past 14 years , with 2021 seeing more data breaches reported than any other year since records first started being published by OCR. … Between October 21, 2009, when OCR first started publishing summaries of data breach reports on its“Wall of Shame” , and December 31, 2023, 5,887 large healthcare data breaches have been reported. On January 22, 2023, the breach portal listed 857 data breaches as still under investigation. This time last year, there were 882 breaches listed as under investigation, which shows OCR has made little progress in clearing its backlog of investigations – something that is unlikely to change given the chronic lack of funding for the department.
You didn’t think I’d leave you hanging, did you?
Here’s the Wall of Shame.
As of this writing, there are 750 cases between 02/17/2023 and 09/24/2025.
We’re a full-service facility, so I ran the math for you. The total tally came to 293,171,305 individuals affected. There’s likely some overlap, but I think we can all agree that’s a lot of breaching!
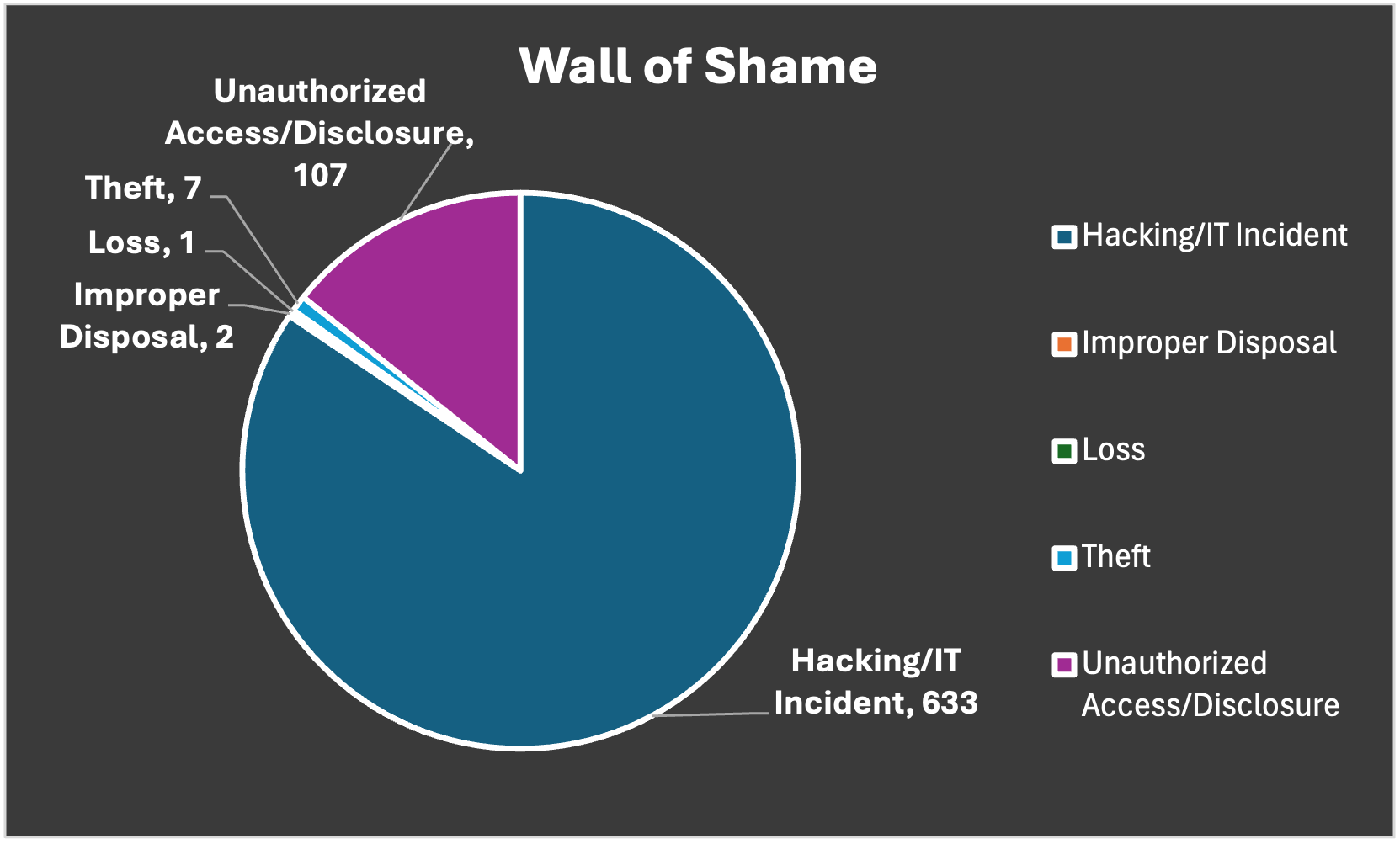
What’s more, the vast majority of these incidents (633) were marked as
The point is, trusting your healthcare data to an external entity may not guarantee that it will remain private. Since we’re being idealistic, let’s assume there will be a future where the data can be kept under your direct control. If that were so, you may want to make sure it was safe and manage who could view how much of it.
Also, to be fair to the healthcare industry, this problem is not exclusive to them. The US Center for Strategic and International Studies maintains a list of Significant Cyber Incidents that, trust me, will make your toes curl.
It’s a real big probl…

OK, I’ll shut up. You get the point. Other people can not be trusted with our data.
Access

OK, let’s say we live in a magical wonderland where all your private data is stored in a super-secure database under your own control. Not everyone needs to be given access to every element everywhere. Remember those lenses we talked about? You would want to provide access to subsets for specific purposes.
Also, not everyone needs to know every piece of data to the same, exacting detail. For example, you may want to tell a friend your exact address so they can come over for dinner, but a marketing firm typically only needs the city or state to run their advertising campaign. Today, you’re being asked to enter your full address data every time you sign up for a service or conduct a financial transaction. It’s all or nothing. You’re not even told why they need that information. If it’s to authenticate you, we’ve already established that getting that information is pretty straightforward.
So let’s pretend it’s for authentication and recognize that it’s so they can resell it, resulting in an overwhelming amount of junk mail solicitations.
But what if we designate a Blur Level for each data element, where it changes the fuzziness of the data.
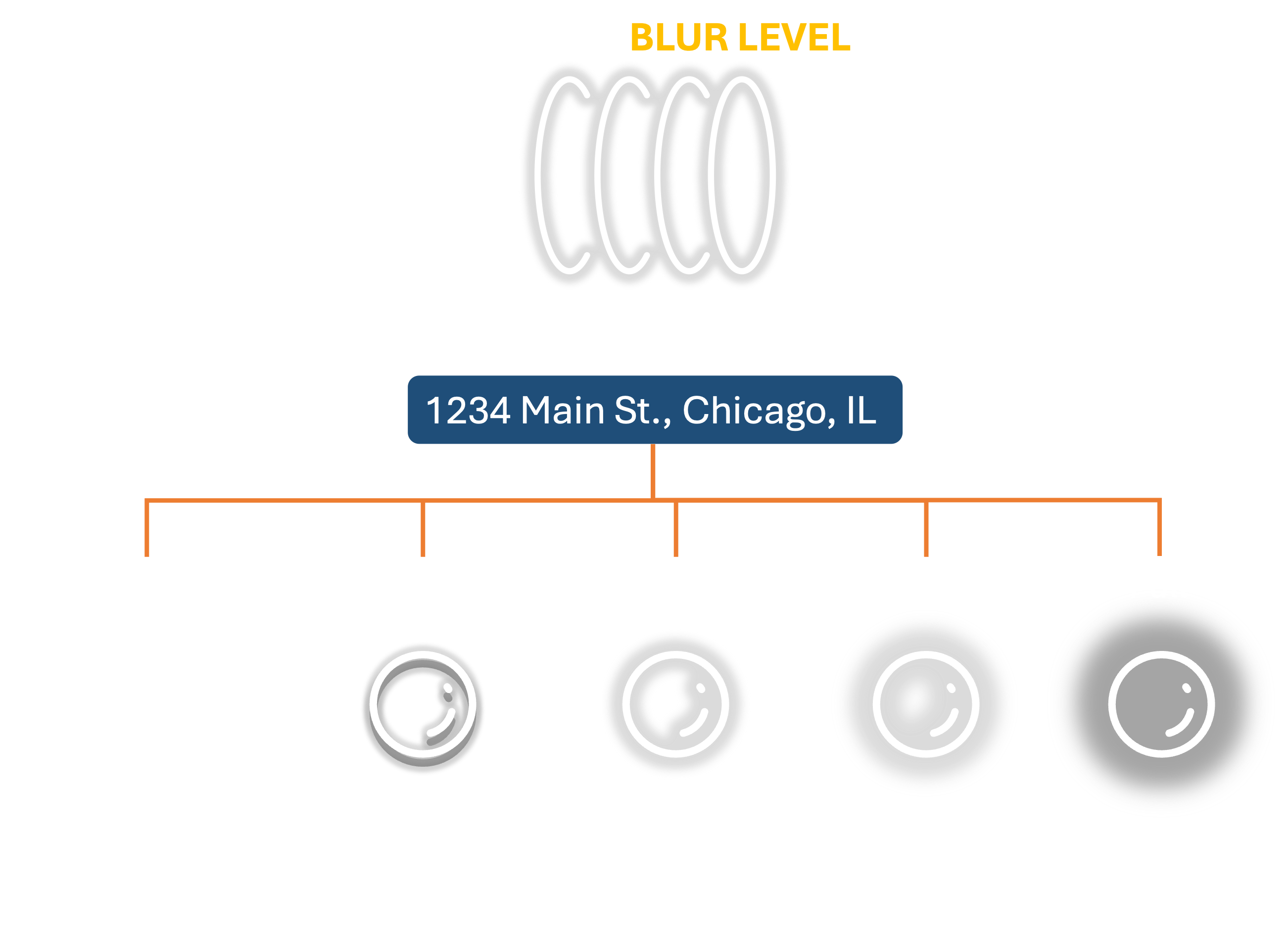
This will let you keep the original data intact, but manage how much visibility you want to give to others.
But wait, visibility is just one element of giving others access. There are a range of other things you may want to control, like who can see what, for how long, for what purpose, how often, and when should that access be expired or rescinded.

This is a lot. I know.
And this list isn’t even exhaustive. There are many other types of fine-grain control we could offer. For example, if the data is stored hierarchically (above), then we may want to give access to data we own, but not the list of our relationships, such as our children, friends, siblings, coworkers, etc.
And let’s be honest. Who has time to manage all this? I sure don’t. We would need tools or mechanisms to help us manage these and keep track of all of them.
Perhaps even smart mechanisms, displaying some sort of innate artificial intelligence.

Don’t jump ahead. We’ll get to that.
Blast Radius
In military jargon, a blast radius is how far shrapnel travels after an explosion. In cybersecurity, it describes the extent of damage a security incident can cause.
In sugary, sticky drink-based incidents, it has a whole other meaning.

If all our private data were stored in a single database and the database was breached, the potential blast radius could be catastrophic.
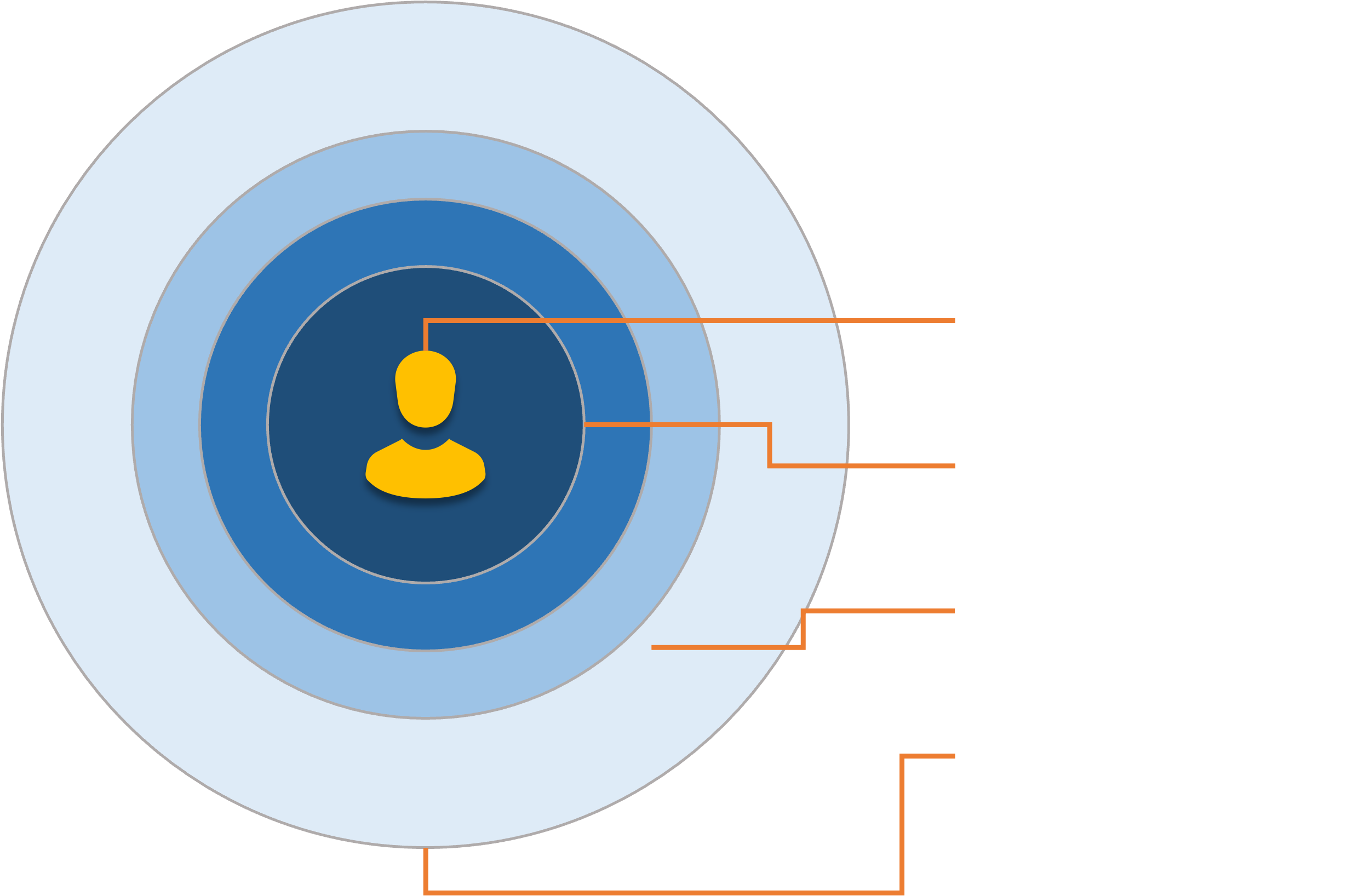
However, if we had applied blur to the data, the damage could have been limited.
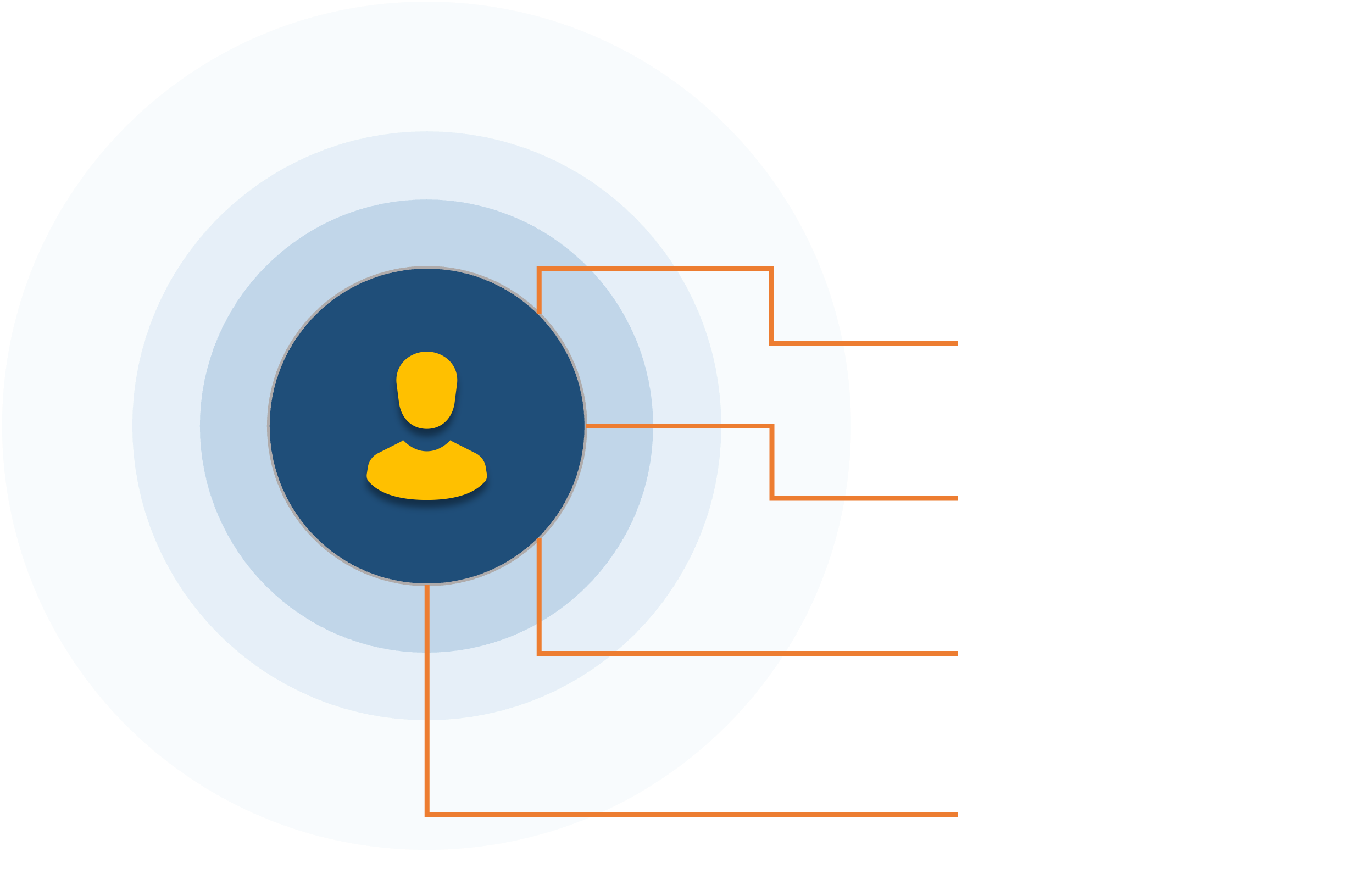
Remember those lenses? They could each come with preset blur values associated with different data types, in case we don’t want to fiddle with every single data element.
But what if one of those clever hackers (or nation states) managed to find the keys to the kingdom and get access to your whole personal database?
This is where the concepts of encryption, authorization, and attestation come in handy, and we’ll explore them.

Before you click away, this may be a good time to take a break and calm your mind.

Attestation
Welcome back.

The dictionary definition we’re most interested in is:
b:
an official verification of something as true or authentic
This means we want a system where any entity accessing or offering data can be verified as authentic. There are several methods and techniques already out there, ranging from casual to highly intrusive. We need to provide access via a trusted intermediary who can vouch that everyone involved is who they claim to be and has the necessary authorization to perform the required tasks.
For example, a healthcare provider will want to know they’re accessing data from their actual patient, and the patient wants to confirm the person looking at the data on the festering boil on their toe is their actual podiatrist.
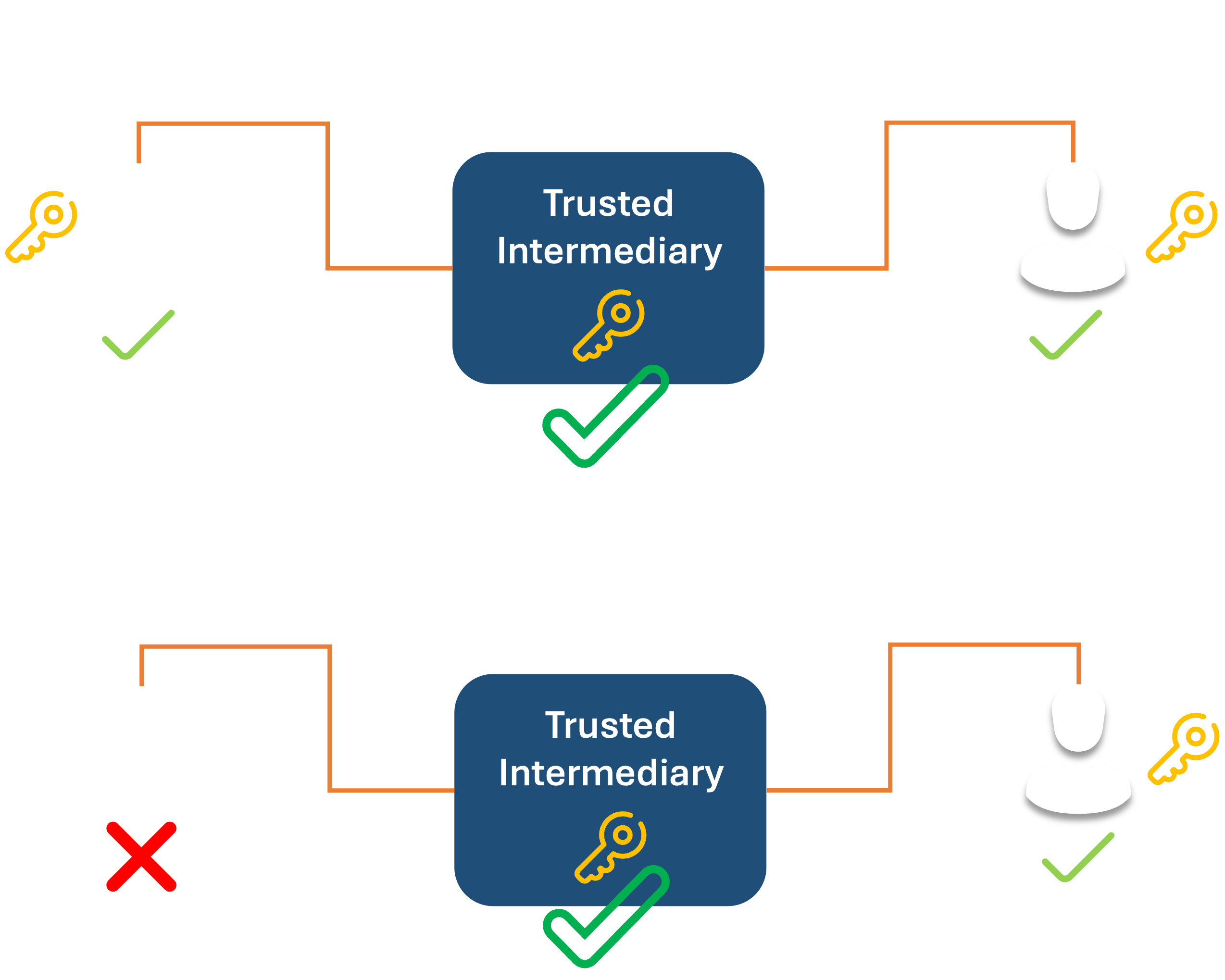
Both will need to access the mechanism through which they are communicating.
# Side NoteAgain, remember we are in a magical wonderland where this can be accomplished with the least amount of convenience and all the thorny problems are solved.
I know I’m hand-waving here, but I don’t want to go down that particular rabbit-hole and embark on what the hip folks call solutioning just yet. For now, we want to stay focused on Privacy as it relates to AI Companions and our interactions with and through them.
For this to work, we need to provide a secure mechanism that is not too cumbersome to use and offers both sane defaults and fine-grained control over access to our private data.
It may be centralized, distributed, federated, open-source, commercial, cloud-based, or at the edge. At this point, we don’t care about the detailed architecture as long as it gives us what we need, which is control over our own data.
Encryption
Remember where we talked about where our private data was stored and the blast radius if it were breached? There are actually two ways the data could be accessed:
- In Transit: during transmission
- At Rest: kept in a data store
![]()
The internet has had a long and torturous history of creating infrastructure to handle end-to-end encryption. Technologies like SSL, TLS, & https. There is also an associated mechanism for managing SSL/TLS Certificates and a network of Certificate Authorities. I won’t delve too deeply into it, but if you’re interested, follow those links.
The goal is to prevent sending cleartext data if someone is sniffing the wires or presenting themselves as a trusted intermediary to perform Man-in-the-middle attacks.
That’s for encrypting data as it moves about. There’s also a corresponding mechanism for encrypting the data while at rest.
The idea here is that in case someone gets access to the physical storage media housing the data. The theory is that if they got the disk, it would only be filled with green, encrypted gibberish.

In addition to all that, protocols are needed to prevent unauthorized access to the systems where the data is stored. It doesn’t matter if the data is encrypted in transit or at rest if malicious actors can just waltz right in the front door and hold the data hostage to collect ransomware:
In February 2024, Change Healthcare suffered a ransomware attack that resulted in file encryption and the theft of the protected health information of an estimated 190 million individuals. The stolen data included
names, contact information, dates of birth, Social Security numbers, and medical information , and is the largest healthcare data breach ever reported.
Ransomware is evil, but clever. It’s like you still have the key to your home, but someone’s installed an extra padlock on the gate and won’t give you the key unless you pay them.

They don’t need to crack your lock and reverse engineer your alarm code. Just prevent the owner from getting in.
Strangely, the Change Healthcare story states that it was ransomware, but they also obtained copies of the stolen data. Maybe they also found the encryption key under a mat. Or perhaps the data wasn’t encrypted adequately at rest.
Let’s also give the benefit of the doubt and assume the breach reports are accurate despite the wildly varying estimates:
Change Healthcare initially reported the data breach to the HHS’ Office for Civil Rights using a placeholder figure of
500 affected individuals . The estimate was revised to100 million , before being increased again to190 million .
What can we do to prevent the blast radius of these breaches?
If multi-billion-dollar companies with all manner of security and training, and oodles of cybersecurity consultants, can’t stop people from breaking in and taking everything, what can you and I do to protect our own data?
Other People’s Data (OPD)
The data collected by any third-party – government agency, school, business, or healthcare provider – belongs to them, right? Even if it’s about you?
If all the headlines above are any indication, these folks are terrible at protecting that data. All these valuable records stored in a single location. It’s like the motherlode. Someone breaks in, sweeps it all out and you got yourself a headline-worthy, eye-popping breach.
What if instead, every user owned their own data and allowed that third-party to save the data
Multi-Factor Obfuscation
One way is to well, lie.

I don’t mean intentionally tell untruths. What I mean is that the data stored and transferred is not precisely the actual data, but an altered version of it. This means that if someone accesses it in transit, at rest, or through a breach, they would still be looking at partial data.
What would happen is the equivalent of Multi-factor authentication, where you need two or more pieces of information before you are given access to a system.
Many of us are now familiar with having to enter a username and password, as well as a second factor, via either email, text, phone call, or a custom hardware key.
What if we did something similar with access to the actual data?
Except that instead of presenting the two factors to access the data, the data is literally in two (or more) pieces. Each part would be useless without having all the parts.
Think of it like one of those twin-tube Epoxy glues that need to be mixed before use.

What if you kept each part of your data separate, with its own access keys, and only at the last minute, when needed, would they be combined to reveal the complete information?
At the point of accessing each one, the system could also apply whatever attestation, blur, and access rules you have specified for each individual element.
And to keep things more fun and exciting, for each element, there could be a different mechanism to transform the real data to and from the gibberish version. Let’s refer to each of these as transforms, and let the raw, garbled data and the transformed data be kept in separate places.
![]()
At the point of saving your data, the system applies a different perturbation mechanism to each element to make it garbled. For example, for a number value, if the original was 100, it could add 428 to it and save it as 528. Regarding data storage, it would be 528. But in a separate transform storage, there would be an indication that the record is using an addition transform with a value of 428. The system would combine the two and reverse the action: subtract 428 from 528 to get the actual 100 value.
Of course, this is a cartoonishly simple example. There would be other, more complex transformations that break down text into pieces, replace letters with others, or encrypt them using one or more private keys. And these would be cryptographically complex, reversible, and verifiable.
Anyone breaching the data store would get encrypted, but ultimately wrong data. They would need to access both the data storage and the transform storage to be able to put the two epoxy glue bits back together. Each item by itself would be useless. Reassembling could only be done at the last point when the data is needed – right before interacting with an authorized user.
![]()
This is a very simplified version, but hopefully you get my point.
Ah! You might say. There are problems with this system.

Let’s take them one at a time:
# 1. If someone broke into one system, why can't they break into another?▶ 1. If someone broke into one system, why can't they break into another?
# 2. Won't this take more storage space?▶ 2. Won't this take more storage space?
# 3. Won't this require more processing power?▶ 3. Won't this require more processing power?
# 4. Can't someone just snag the data after they've been combined?▶ 4. Can't someone just snag the data after they've been combined?
# 5. I bet someone's already come up with this.▶ 5. I bet someone's already come up with this.
Footprints
Anywhere you go online, you leave tracks of where you have been and what you have done. For example, every time you connect to a mail server to check your own e-mail, there is a behind-the-scenes handshake between your mail client (or web page) and the mail server.
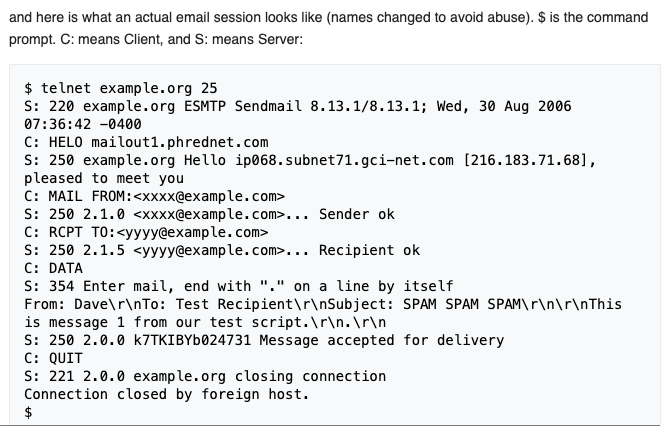
On the server side, there is a log record of every exchange or transaction, including the sender, recipient, time, IP address of the client, and the contents of the email message.
From your IP address, they can even deduce your rough geographic location (or that of your Internet Service Provider).
The same is true when you visit a website.
The web server on the other end has detailed information about your interactions, conveniently stored in Common Log Formats. Most of the time, these logs are purged or archived, but we have no idea how often or for how long. Storage is inexpensive enough that it’s likely to be kept for years, decades, or even forever.
In the era of AI, Data is King, so it’s unlikely any self-respecting web service will purge and throw away any hard-earned data. Like a hoarder, they will hold on to it even if they have no immediate use, in case it may be needed at some point in the future.

Presumably, we trust the web service with which we are interacting. After all, not every store we purchase goods from is going to scan our faces, track our ATM or credit card numbers, and keep a record of what we’ve purchased.
Are they?
Those loyalty/discount cards where you get 2-for-1 deals?
OK, yes. Maybe they are tracking us. But there’s nothing to worry about. It’s not like retailers like grocery stores are becoming data brokers.

If this is making you feel hopeless that you don’t know what’s being done with the data collected, cheer up! At least you’re not alone.

OK, let’s step back. The point of this section isn’t to make you paranoid about the modern world and turn us into underground, off-grid mole-people.
However, when it comes to AI Companions, it would be preferable if they didn’t use our private data, including contacts, emails, messages, purchases, interactions, inner thoughts, and private emotions, as fodder for the data mill.
This is why we should have Trusted Intermediaries.

At some point, we all need to trust someone.
# Side NoteI wouldn’t trust me. I’m merely providing one perspective and offering what I think may be a solution.
But every individual needs to decide and make informed decisions for themselves.
If you fall under the I Don’t Have Anything to Worry About group, please continue.
However, if you fly the My Data is My Own flag, you will be pleased to know that technology offers a range of tools to allow you to lock things down. But only up to a point. Besides, they are generally a pain to deploy and use.
We need something simpler, like a personalized slider.

Our challenge as technologists is to create user-friendly, frictionless, secure, and comprehensive solutions that meet these requirements.
Like a slider.
Even better, one that automatically adapts to your needs without requiring you to take any explicit steps.
Does such a thing exist?

We really, really should build one.
Title Photo by Christal Yuen on Unsplash